Описательная статистика
Понятие выборки
Математическая статистика – наука о математических методах, позволяющих по статистическим данным сформулировать выводы о свойствах изучаемого массового явления.
На практике редко доступна полная информация о модели изучаемого явления, описываемого в терминах некоторой случайной величины X. Чаще о законе распределения X имеется лишь частичная информация либо никакой априорной информации о распределении X вообще нет. В этом случае возникают задачи восстановления параметров или вида неизвестного распределения FX или определения его свойств.
Задачи математической статистики являются, в некотором смысле, обратными к задачам теории вероятностей. Если теория вероятностей позволяет при заданной вероятностной модели вычислить вероятности тех или иных случайных событий, то математическая статистика по результатам проводимых наблюдений (по исходам эксперимента) уточняет структуру вероятностной модели изучаемого явления.
Математическая статистика решает следующие задачи:
1) систематизация полученного статистического материала (этап описания массового явления);
2) выявление свойств и закономерностей изучаемого явления (этап анализа и прогноза).
Первой задачей занимается раздел математической статистики, называемый описательной (дескриптивной) статистикой. Описательная статистика предоставляет методы первичной обработки эмпирических данных, их наглядного представления в форме графиков и таблиц, а также их количественного описания посредством основных статистических показателей. Методы описательной статистики, как правило, не требуют предположений о вероятностной природе данных.
Решению второй задачи посвящены теория оценивания и теория проверки статистических гипотез. В основе этих теорий лежат методы построения математических моделей наблюдений и статистических закономерностей.
Точечное оценивание – вычисление приближённых значений характеристик статистических закономерностей по результатам наблюдений.
Интервальное оценивание – построение случайных множеств, называемых доверительными, которые с заданной вероятностью содержат оцениваемые характеристики.
Проверка статистических гипотез – принятие или отклонение по реализации наблюдений априорного предположения о неизвестных характеристиках статистических закономерностей.
С особенностями различных постановок задач оценивания связаны и различия соответствующих статистических исследований.
Центральным понятием математической статистики является выборка. Выборка понимается следующим образом. Пусть случайная величина X наблюдается в эксперименте с комплексом условий G. Результатом этого эксперимента будет некоторое случайное число x – реализация случайной величины X. Повторим эксперимент n раз с неизменным комплексом условий. Результатом такого эксперимента будет случайный вектор (x1,…,xn), где xj – реализация случайной величины X в j-м эксперименте. С другой стороны, вектор (x1,…,xn) можно рассматривать как единственную реализацию случайного вектора (X1,…,Xn), где случайные величины X1,…,Xn независимы в совокупности и каждая из которых имеет тот же закон распределения, что и случайная величина X.
Совокупность всех наблюдений случайной величины X, которые могли бы быть сделаны при данном комплексе условий, называется генеральной совокупностью случайной величины X, или просто генеральной совокупностью X. Распределение случайной величины X называется распределением генеральной совокупности. Число элементов, входящих в генеральную совокупность, называют объёмом генеральной совокупности. Объём генеральной совокупности может быть как конечным, так и бесконечным.
Совокупность независимых случайных величин X1,…,Xn, каждая из которых имеет то же распределение, что и наблюдаемая случайная величина X, называется случайной выборкой из генеральной совокупности X. При этом число n называют объёмом случайной выборки, а случайные величины X1,…,Xn – элементами случайной выборки. Любую реализацию x1,…,xn случайной выборки X1,…,Xn будем называть выборкой из генеральной совокупности X, или выборочной совокупностью. Выборка из генеральной совокупности X представляет собой некоторое подмножество этой генеральной совокупности.
Пример 1. Эксперимент состоит в подбрасывании правильной игральной кости. Случайная величина X – число очков, выпавшее на верхней грани, возможные значения случайной величины X: 1,…,6. В результате эксперимента получаем случайное число x – реализацию случайной величины X, . При повторении эксперимента n раз получаем выборку x1,…,xn наблюдений случайной величины X, , , или, что то же самое, единственное наблюдение случайной выборки X1,…,Xn объёма n. Генеральная совокупность случайной величины X содержит бесконечное число значений 1,…,6 в равных пропорциях.
Пример 2. Исследуется качество партии выпущенных предприятием изделий. Случайная величина X – индикатор брака в изделии – принимает значение 1, если изделие оказалось бракованным, и 0 – в противном случае. В результате наблюдения случайной величины X (выбирая случайным образом изделие) получаем её реализацию x (0 или 1). Обследуя n изделий, получаем выборку наблюдений x1,…,xn, , . Объём генеральной совокупности определяется объёмом партии выпущенных изделий. Объём выборки n не может превышать объём генеральной совокупности.
Понятие выборки может быть обобщено на случай, когда в результате эксперимента с некоторым комплексом условий G наблюдается несколько случайных величин. Например, пусть (x, y) – наблюдение двумерного случайного вектора (X, Y). Тогда случайная выборка объёма n представляет собой последовательность (X1, Y1),…,(Xn, Yn) случайных векторов, а её реализация – последовательность векторов (x1, y1),…,(xn, yn).
Способы представления выборки
Результаты наблюдений x1,…,xn генеральной совокупности X, записанные в порядке их регистрации, обычно труднообозримы и неудобны для дальнейшего анализа. Одной из задач описательной статистики является получение такого представления выборки, которое позволит выявить характерные особенности совокупности исходных данных.
Одним из самых простых преобразований статистических данных является их упорядочивание по величине. Вариационным рядом выборки x1,…,xn называется способ её записи, при котором элементы упорядочиваются по возрастанию, т.е. вариационный ряд выборки – это последовательность чисел
,
удовлетворяющих условию .
Вариационный ряд выборки x1,…,xn можно рассматривать как реализацию вариационного ряда случайной выборки X1,…,Xn. Случайную величину X(i) называют i-й порядковой статистикой (ith order statistic). Число x(i) называют i-м членом вариационного ряда, или реализацией i-й порядковой статистики. Крайние члены X(1) и X (n) вариационного ряда называются экстремальными порядковыми статистиками. Для любой выборки реализации экстремальных порядковых статистик – это её минимальное и максимальное значения.
Можно показать, что функции распределения экстремальных порядковых статистик имеют вид:
|
, |
|
. |
Эти соотношения позволяют оценить неизвестную функцию распределения FX(x) генеральной совокупности X, имея в эксперименте лишь минимальные и максимальные значения выборок.
Разность между максимальным и минимальным элементами выборки x(n) – x(1) называется размахом выборки (range of a sample).
Различные значения случайной величины X называются вариантами.
Пусть выборка x1,…, xn случайной величины X содержит k вариантов z1,…,zk, причём вариант zi встречается ni раз (i = 1,…,k). Число ni называется частотой варианта zi. Очевидно, что сумма частот всех вариантов равна объёму выборки, .
Статистическим рядом называется последовательность пар (zi, ni), i = 1,…,k. Обычно статистический ряд записывается в виде таблицы, первая строка которой содержит варианты zi, а вторая – частоты ni (табл. 1.1), при этом варианты записываются в порядке возрастания.
Таблица 1.1
Статистический ряд выборки
Варианты, zi |
z1 |
... |
zi |
... |
zk |
Частоты, ni |
n1 |
... |
ni |
... |
nk |
В частном случае, если все элементы выборки различны, то k = n, а частоты всех вариантов равны единице.
При большом числе вариантов (например, при наблюдении случайной величины непрерывного типа с высокой точностью измерений) выборка может быть представлена в виде группированного статистического ряда. Для этого отрезок [x(1); x(n)], содержащий все элементы выборки, разбивается на k непересекающихся интервалов J1 = [α0 = x(1); α1), J2 = [α1; α2),…, Jk = [αk-1; αk = x(n)], как правило, одинаковой ширины h. Правые границы всех интервалов, за исключением последнего, задаются открытыми, чтобы исключить попадание граничных точек в соседний интервал.
Число интервалов k выбирают, как правило, в зависимости от объёма выборки. Для ориентировочной оценки числа k можно воспользоваться формулой Стерджесса (Herbert Sturges, 1926):
,
где оператор означает взятие целой части.
Например, при n = 100 оценка числа интервалов по формуле Стерджесса даёт k ≈ 7, при n = 1000: k ≈ 10.
Ширина группировочных интервалов и число групп связаны формулой
|
. |
Более теоретически обоснованный подход к выбору ширины группировочных интервалов дают формула Скотта (David Scott, 1979):
,
и формула Фридмана (David Freedman, 1981):
,
где s – среднеквадратичное отклонение выборки, Δ – интерквартильный размах выборки. Число группировочных интервалов k определяется из (3).
В случае если распределение генеральной совокупности существенно отличается от нормального, число интервалов может быть увеличено. С уменьшением числа интервалов k происходит потеря статистической информации, содержащейся в исходной выборке.
Группированным статистическим рядом называется последовательность пар (Ji, ni), i = 1,…,k. Группированный статистический ряд записывается в виде таблицы, первая строка которой содержит интервалы Ji, а вторая – частоты ni. Иногда в группированном статистическом ряде в первой строке таблицы вместо интервалов J1,…,Jk записывают середины интервалов c1,…,ck, где – середина i-го интервала.
Наряду с частотами ni, i = 1,…,k, попадания выборочных значений в группировочные интервалы рассматриваются также:
– относительные частоты ni / n;
– накопленные (cumulative) частоты ;
– относительные накопленные частоты mi / n.
Полученные результаты сводятся в таблицу, называемую таблицей частот группированной выборки (табл. 1.2).
Таблица 1.2
Таблица частот группированной выборки
Номер интервала, i |
Границы интервала |
Середина интервала, ci |
Частота, ni |
Накопленная частота, mi |
Относительная частота, ni / n |
Накопленная относительная частота, mi / n |
1 |
[α0; α1) |
c1 |
n1 |
m1 |
n1/n |
m1/n |
... |
... |
... |
... |
... |
... |
... |
k |
[αk-1; αk] |
ck |
nk |
mk = n |
nk/n |
mk/n = 1 |
Визуально таблица частот может быть представлена с помощью гистограмм и полигонов частот. Выделяют 4 типа гистограмм (полигонов) частот:
1) гистограмма (полигон) абсолютных частот;
2) гистограмма (полигон) относительных частот;
3) гистограмма (полигон) накопленных частот;
4) гистограмма (полигон) относительных накопленных частот.
Гистограмма частот представляет собой кусочно-постоянную функцию, принимающую постоянные значения внутри интервалов группировки. В зависимости от типа гистограммы это значение может быть абсолютной частотой, относительной частотой, накопленной частотой или относительной накопленной частотой.
Полигоны абсолютных и относительных частот строятся следующим образом: если построена соответствующая гистограмма частот, то ординаты, соответствующие средним точкам интервалов, последовательно соединяются отрезками прямых.
Полигоны накопленных частот и относительных накопленных частот строятся так: если построена соответствующая гистограмма частот, то ординаты, соответствующие правым точкам интервалов, последовательно соединяются отрезками прямых.
Эмпирическая функция распределения. Числовые характеристики выборки
Пусть x1,…,xn – выборка наблюдений случайной величины X, имеющей распределение FX(x). Пусть выборка содержит k вариантов z1,…,zk, причём вариант zi встречается с частотой ni, .
Введём случайную величину дискретного типа , принимающую значения z1,…,zk с вероятностями, равными соответствующим относительным частотам n1/n,…,nk/n, т.е. , . Относительные частоты принадлежат отрезку [0; 1], причём их сумма равна единице, т.е. для относительных частот выполнены все требования, предъявляемые к вероятности распределения. Распределение случайной величины называется распределением выборки x1,…,xn (табл. 1.3).
Таблица 1.3
Распределение выборки
Значения, zi |
z1 |
... |
zi |
... |
zk |
Вероятности, pi |
nj / n |
... |
ni / n |
... |
nk / n |
В связи с тем, что в выборке может присутствовать лишь конечное (или счётное) число вариантов наблюдаемой случайной величины X, распределение случайной величины всегда является дискретным.
Функция распределения случайной величины называется эмпирической (выборочной) функцией распределения (ЭФР ) и обозначается :
.
Как известно, функция распределения случайной величины дискретного типа представляет собой кусочно-постоянную функцию. График ЭФР для выборки x1,…,xn с вариантами z1,…,zk приведён на рисунке ниже. Несложно показать, что ЭФР может принимать лишь значения, равные накопленным относительным частотам вариантов z1,…,zk либо равняться нулю:
|
|
В точках z1,…,zk ЭФР претерпевает разрыв непрерывности и является, как и любая функция распределения, непрерывной слева.
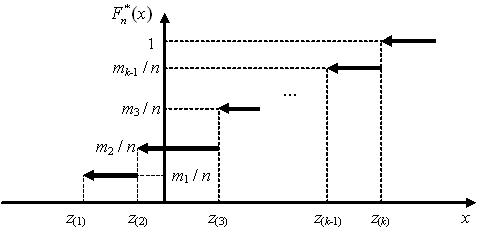
Поскольку ЭФР выборки x1,…,xn является функцией распределения дискретной случайной величины , то для неё справедливы все свойства функции распределения дискретной случайной величины.
Эмпирическую функцию распределения выборки x1,…,xn можно рассматривать как реализацию случайной эмпирической функции распределения соответствующей случайной выборки X1,…,Xn. При каждой конкретной реализации случайной выборки получаем соответствующую ей реализацию случайной ЭФР.
Выборочными (эмпирическими) числовыми характеристиками называются числовые характеристики случайной величины . К таким характеристикам относятся, например, моменты случайной величины. Напомним, что зная функцию распределения fX(x) случайной величины X (или распределение вероятностей p1,…,pk для случайной величины дискретного типа), математическое ожидание элементарной действительной функции ξ(X) случайной величины X рассчитывается по формулам:
и
для непрерывного и дискретного случаев соответственно.
Учитывая (2), запишем выражение для расчёта выборочного начального момента r-го порядка. Все выборочные числовые характеристики будем обозначать с верхним знаком «звёздочки»:
В связи с тем, что каждый вариант zi встречается в выборке x1,…,xn с соответствующей частотой ni, , каждое произведение может быть записано как сумма ni одинаковых элементов выборки, равных варианту zi. Таким образом, выражение (3) примет вид:
Выражение (3) называется взвешенной формой записи выборочного начального момента r-го порядка, а выражение (4) – невзвешенной.
Взвешенная форма записи выборочного начального момента r-го порядка представляет собой среднее арифметическое различных элементов (вариантов) выборки, возведённых в r-ю степень и взвешенных их частотами. Из невзвешенной формы записи видно, что выборочный начальный момент r-го порядка представляет собой простое среднее арифметическое элементов выборки, возведённых в r-ю степень. В связи с этим нередко выборочный начальный момент r-го порядка обозначается через .
Выборочный начальный момент первого порядка называется выборочным математическим ожиданием и представляет собой простое среднее арифметическое элементов выборки, в связи с чем нередко обозначается через :
Нижний индекс ‘X’ в обозначении выборочного математического ожидания и других выборочных характеристик определяется случайной величиной, наблюдениями которой являются рассматриваемые выборочные значения x1,…,xn.
Операция центрирования выборки состоит в смещении её значений на :
.
Выборочное математическое ожидание (среднее) центрированной выборки ε1,…,εn равно нулю:
.
Учитывая определение центрального момента r-го порядка случайной величины дискретного типа, запишем выражение для расчёта выборочного центрального момента r-го порядка:
Выражение (6) является взвешенной формой записи. Невзвешенная форма получается из взвешенной заменой произведений , , на сумму ni одинаковых слагаемых:
.
Выборочный центральный момент второго порядка называется выборочной дисперсией:
Выборочная дисперсия является мерой рассеяния выборочных значений x1,…,xn относительно их среднего арифметического .
Выборочное среднеквадратичное отклонение (с.к.о.) выборки x1,…,xn определяется как квадратный корень из выборочной дисперсии :
.
Для выборочных начального и центрального моментов применимы все тождества, справедливые для начального и центрального моментов случайной величины дискретного типа. В частности, полезное на практике соотношение между выборочной дисперсией и выборочным начальным моментом второго порядка:
Это равенство следует читать как «выборочная дисперсия равна разности между средним квадратом и квадратом среднего».
Выборочный коэффициент асимметрии (skewness) и выборочный эксцесс (kurtosis) – это коэффициент асимметрии и эксцесс случайной величины :
,
,
Выборочный коэффициент асимметрии характеризует степень асимметрии, а эксцесс – степень «плосковершинности» распределения выборки.
Выборочные характеристики могут быть рассчитаны для группированной выборки. Пусть проведена группировка выборочных данных x1,…,xn на k интервалов [α0; α1), [α1; α2),…, [αk-1; αk]; ni – частота попадания выборочных значений в i-й интервал, – середина i-го интервала, .
При расчёте выборочных характеристик группированной выборки предполагается, что все элементы выборки, попавшие в i-й интервал, находятся в середине интервала. Таким образом, выборочный начальный момент r-го порядка рассчитывается как среднее арифметическое взвешенное середин интервалов, возведённых в r-ю степень, а выборочный центральный момент r-го порядка – как среднее арифметическое взвешенное центрированных середин интервалов, возведённых в r-ю степень. В обоих случаях взвешивание проводится частотами попадания в интервалы:
Выборочной квантилью на уровне вероятности p (или порядка p) выборки x1,…, xn называется квантиль случайной величины на уровне вероятности p. Напомним, квантилью случайной величины X называется точная верхняя граница xp множества значений x, для которых выполнено условие:
.
Для дискретной случайной величины, в частности, для случайной величины , точная верхняя граница этого множества не может быть определена однозначно. В связи с этим для расчёта выборочной квантили на практике используются следующие правила.
1. Значение i-го элемента вариационного ряда x(i) является выборочной квантилью порядка pi = (i – 0,5) / n. Таким образом, соответствие между элементами вариационного ряда и порядком квантилей устанавливается таблицей
Выборочная квантиль, |
x(1) |
... |
x(i) |
... |
x(n) |
Порядок, p |
0,5 / n |
.. |
(i – 0,5) / n |
.. |
(n – 0,5) / n |
2. Для расчёта квантили произвольного порядка p, 0 ≤ p ≤ 1 используется линейная интерполяция значений, приведённых в таблице выше.
Выборочной медианой выборки x1,…, xn называется выборочная квантиль на уровне p = 0,5. Из правил расчёта выборочных квантилей следуют правила расчёта выборочной медианы.
1. Если объём выборки n – нечётный, то, разрешая уравнение (i – 0,5) / n = 0,5 относительно i, получаем номер элемента вариационного ряда, являющегося медианой, т.е.
.
2. Если объём выборки n – чётный, то выборочная медиана определяется путём линейной интерполяции элементов вариационного ряда с номерами и , имеющих порядки квантилей и соответственно. Результатом этой интерполяции будет среднее значение
Выборочные квантили и на уровнях 0,25 и 0,75 называют выборочными нижней и верней квартилями соответственно. Разность Δ между верней и нижней квартилями называется интерквартильным интервалом:
.
Интерквартильный интервал является характеристикой разброса выборочных значений и является, в некотором смысле, аналогом дисперсии.
Выборочные квантили ,…, на уровнях, кратных 0,1, называются выборочными децилями, а выборочные квантили ,…, на уровнях, кратных 0,01, – выборочными процентилями.
Выборочной модой выборки x1,…, xn с вариантами z1,…,zk называется вариант zi, , частота ni которого максимальна.
Выборочные характеристики двумерного случайного вектора
Выборочные характеристики можно ввести и для выборок из многомерных генеральных совокупностей. Пусть (x1, y1),…,(xn, yn) – выборка наблюдений двумерного случайного вектора (X, Y), имеющего распределение FXY(x, y). Пусть выборка содержит k различных пар наблюдений (вариантов) z1,…,zk, , причём вариант zi встречается с частотой ni, .
По аналогии с одномерным случаем введём случайный вектор дискретного типа , принимающий значения z1,…,zk с вероятностями, равными соответствующим относительным частотам, n1 / n,…, nk / n, т.е. , .
Распределение случайного вектора называется распределением двумерной выборки. Предварительное представление о распределении выборки можно получить, изображая элементы выборки точками на плоскости координат xOy. Это представление выборки называется диаграммой рассеяния (scatter plot).
Выборочными числовыми характеристиками двумерной выборки (x1, y1),…, (xn, yn) называются числовые характеристики случайного вектора . К таким характеристикам относятся, например, моменты случайного вектора.
Выборочный смешанный начальный момент порядка (q + r) равен:
где , а суммирование проводится по всем вариантам случайного вектора .
Учитывая, что случайный вектор принимает вариант (xi, yi) с вероятностью, равной относительной частоте ni этого наблюдения в выборке, и, представляя произведения как суммы ni одинаковых слагаемых , , формула (1) может быть записана в виде:
.
Аналогично, выборочный смешанный центральный момент порядка (q + r) определяется формулой:
.
Наиболее часто используемой числовой характеристикой двумерного вектора является коэффициент корреляции. Напомним, что для случайного вектора дискретного типа (X, Y) коэффициент корреляции rXY определяется следующим образом:
где kXY – ковариационный момент, по определению .
Учитывая (2), определим выражение для выборочного коэффициента корреляции :
,
где – выборочный ковариационный момент:
.
Для выборочных ковариационного момента и коэффициента корреляции применимы все тождества, справедливые для ковариационного момента и коэффициента корреляции случайного вектора дискретного типа. В частности, полезное на практике соотношение между выборочным ковариационным моментом и выборочным смешанным начальным моментом второго порядка:
Это равенство следует читать как «выборочный ковариационный момент равен разности между средним произведением и произведением средних».
Двумерная выборка может быть представлена в виде корреляционной таблицы. Корреляционная таблица (табл. 1.4) является аналогом группированного статистического ряда для одномерной выборки.
Для построения корреляционной таблицы отрезок [x(1); x(n)], содержащий все наблюдения случайной величины X, разбивается на l непересекающихся интервалов [α0 = x(1); α1), [α1; α2),…, [αl-1; αl = x(n)], как правило, одинаковой ширины h1. Аналогично отрезок [y(1); y(n)], содержащий все наблюдения случайной величины Y, разбивается на m непересекающихся интервалов [β0 = β(1); β1), [β1; β2),…, [βm-1; βm = y(n)], как правило, одинаковой ширины h2. Правые границы всех интервалов, за исключением последнего, задаются открытыми, чтобы исключить попадание граничных точек в соседний интервал.
Процедуру группировки двумерных выборочных наблюдений можно выполнить непосредственно по диаграмме рассеяния, нанеся на неё сетку горизонтальных и вертикальных прямых, взятых с постоянными шагами h1 и h2 и рассчитав частоты nij попадания выборочных точек в каждый прямоугольник.
, , .
Таблица 1.4
Корреляционная таблица
[β0; β1) |
... |
[βj-1; βj) |
... |
[βm-1; βm] |
|
[α0; α1) |
n11 |
... |
n1j |
... |
n1l |
... |
... |
... |
... |
... |
... |
[αi-1; αi) |
ni1 |
... |
nij |
... |
nil |
... |
... |
... |
... |
... |
... |
[αl-1; αl] |
nl1 |
... |
nlj |
... |
nlm |
Очевидно, что сумма всех частот в корреляционной таблице равна объёму выборки .
Точечные оценки
Свойства точечных оценок
Пусть x1,...,xn – выборка наблюдений случайной величины X, имеющей распределение FX(x). При проведении ряда статистических исследований вид функции распределения наблюдаемой случайной величины зачастую предполагается известным (например, случайная величина имеет нормальное или биномиальное распределение). Неизвестными же являются параметры этого распределения.
Одной из задач математической статистики является оценка неизвестных параметров распределения наблюдаемой случайной величины X по выборке x1,..., xn её наблюдений.
Параметром θ∈Θ распределения FX(x) случайной величины X называется любая числовая характеристика этой случайной величины (математическое ожидание, дисперсия и т.п.) или любая константа, явно входящая в выражение для функции распределения FX(x).
В общем случае будем считать, что распределение FX(x) характеризуется вектором параметров .
Например, пусть масса деталей, изготавливаемых станком, в силу присутствия неточности работы станка является случайной величиной X, имеющей нормальное распределение, но его параметры и неизвестны. Требуется найти приближённое значение этих параметров по выборке наблюдений x1,..., xn масс n изготовленных станком деталей.
Напомним, что любая выборка наблюдений x1,...,xn является реализацией случайной выборки X1,...,Xn. Статистикой Z в математической статистике называется произвольная функция случайной выборки, не зависящая от неизвестных параметров распределения:
.
В связи с тем, что статистика Z является функцией случайных аргументов, Z является случайной величиной. Для каждой реализации x1,...,xn случайной выборки X1,...,Xn получим соответствующую ей реализацию z статистики Z:
,
называемую выборочным значением статистики Z.
Точечной оценкой неизвестного параметра θ∈Θ (или вектора параметров) распределения FX(x) называется произвольная статистика , построенная по случайной выборке X1,...,Xn из генеральной совокупности X и принимающая значения из множества Θ:
Точечная оценка является случайной величиной. Для выборки x1,..., xn может быть рассчитана реализация точечной оценки, или выборочное значение точечной оценки, неизвестного параметра θ∈Θ. Далее точечную оценку и её выборочное значение будем обозначать одинаково через , при необходимости дополнительно оговаривая, является ли случайной величиной или её реализацией.
В соответствии с определением (1) существует бесконечно много точечных оценок неизвестного параметра θ. Формально точечная оценка может не иметь ничего общего с интересующим нас параметром θ. Её полезность для получения практически приемлемых оценок вытекает из статистических свойств, которыми она обладает.
Основные свойства точечных оценок.
1. Состоятельность (Consistency)
Точечная оценка называется состоятельной оценкой параметра θ, если последовательность случайных величин сходится по вероятности к оцениваемому параметру θ при , т.е.
.
Иными словами, для состоятельной оценки вероятность её отклонения от оцениваемого параметра θ на любую малую величину e при увеличении объёма выборки стремится к нулю. Это свойство оценки является очень важным, ибо несостоятельная оценка практически бесполезна. Для несостоятельной оценки её значение, рассчитанное даже для выборки очень большого объёма, может существенно отличаться от значения параметра θ, а увеличение объёма выборки может не улучшать её качество.
Состоятельность оценки может быть проверена, используя достаточное условие состоятельности: если и при , то оценка является состоятельной.
Доказательство этого утверждения следует из второго неравенства Чебышева, согласно которому
.
Переходя к пределу при получаем
,
из чего следует состоятельность оценки .
2. Несмещённость (Bias)
Точечная оценка называется несмещённой оценкой параметра θ∈Θ, если её математическое ожидание равно оцениваемому параметру θ, т.е.
|
. |
Разность называется смещением точечной оценки .
Статистика называется несмещённой оценкой параметра θ, если условие (2) выполнено для любого фиксированного объёма выборки n.
Статистика называется асимптотически несмещённой оценкой параметра θ∈Θ, если числовая последовательность математических ожиданий сходится к оцениваемому параметру θ при , т.е.
.
Несмещённость оценки означает, что реализации этой оценки, рассчитанные для различных реализаций случайной выборки X1,...,Xn объёма n, будут группироваться в среднем около оцениваемого параметра θ.
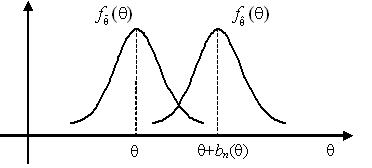
Реализации несмещённой точечной оценки группируются около оцениваемого параметра θ, а реализации смещённой оценки – около величины θ + bn(θ).
3. Эффективность (Efficiency)
Для оценки параметра θ может быть предложено несколько несмещённых оценок. Вследствие несмещённости различные реализации этих оценок будут группироваться относительно их математического ожидания, равного θ, однако разброс этих значений может быть различным. Как известно, мерой разброса значений случайной величины относительно математического ожидания является её дисперсия.
Пусть и – две несмещённые оценки параметра q по выборке объёма n. Оценка называется более эффективной, чем оценка , если её дисперсия меньше, т.е.
Статистика называется более эффективной оценкой параметра θ∈Θ, чем статистика , если условие (3) выполнено для любого фиксированного объёма выборки n.
Если оценка более эффективна, чем оценка , то это означает, что реализации оценки , рассчитанные для различных реализаций случайной выборки X1,...,Xn объёма n, будут иметь меньший разброс около оцениваемого параметра θ, чем реализации менее эффективной оценки .
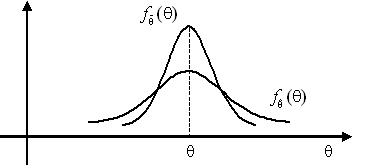
Оценка параметра θ, имеющая минимально возможную дисперсию среди всех оценок, называется эффективной оценкой параметра θ. В математической статистике наряду с термином «эффективная оценка» используют и другие: «несмещённая оценка с минимальной дисперсией», «оптимальная оценка».
Для того чтобы ответить на вопрос, является ли статистика эффективной оценкой параметра θ, используется неравенство Рао-Крамера (Calyampudi Radhakrishna Rao, Harald Cramer, 1945):
,
согласно которому любая оценка параметра θ ограничена снизу величиной при выполнении некоторых условий регулярности (выполнены практически для всех используемых на практике оценок), где In(θ) – количество информации по Фишеру о параметре θ, содержащееся в выборке объёма n.
Таким образом, критерием эффективности оценки является обращение для неё в равенство неравенства Рао-Крамера.
Эффективностью оценки параметра θ называется отношение
.
Согласно неравенству Рао-Крамера эффективность любой точечной оценки ограничена сверху единицей, а для эффективных оценок .
При выполнении условий регулярности каждый элемент независимой случайной выборки X1,...,Xn вносит равный вклад в информацию Фишера In(θ), т.е.
|
, |
где I(θ) – количество информации по Фишеру о параметре θ, содержащееся в одном выборочном наблюдении.
Величина информации по Фишеру зависит от вида распределения генеральной совокупности X. Так, выборки, полученные из генеральных совокупностей с разными распределениями (например, нормальным и биномиальным) будут содержать различное количество информации о неизвестных математическом ожидании или дисперсии.
Чем больше информации по Фишеру о параметре θ содержится в выборочных наблюдениях, тем меньший разброс имеют реализации эффективной оценки этого параметра, а следовательно, являются более точными.
Формально информация по Фишеру о параметре θ, содержащаяся в одном выборочном наблюдении из генеральной совокупности с функцией плотности распределения fX(x, θ), рассчитывается по формуле
|
, |
где функция
называется вкладом выборки.
В случае дискретной генеральной совокупности с распределением вероятностей P(x, θ), , вклад выборки определяется как
|
. |
Статистика является асимптотически эффективной оценкой параметра θ, если последовательность дисперсий сходится к величине, обратной информации Фишера при , т.е.
.
Методы получения точечных оценок
Точечной оценкой неизвестного параметра θ, вообще говоря, может являться любая статистика. Однако на практике интерес представляют лишь наиболее «качественные» оценки, для которых вероятность того, что при реализации случайной выборки они примут значение максимально близкое к неизвестному значению θ наибольшая. Такие оценки должны быть несмещёнными, состоятельными и эффективными. Возникает вопрос, как получить качественную оценку для произвольного параметра θ наблюдаемой случайной величины X?
1. Метод подстановки
Метод подстановки является наиболее простым методом получения точечных оценок. Метод состоит в том, что в качестве оценки неизвестного параметра θ выбирается соответствующая выборочная числовая характеристика:
.
Например, согласно методу подстановки оценкой математического ожидания будет выборочное среднее, а оценкой дисперсии – выборочная дисперсия.
Все оценки, рассчитанные по методу подстановки, являются состоятельными, однако их несмещённость и эффективность не гарантированы. Примером смещённой оценки, рассмотренной ранее, является выборочная дисперсия.
2. Метод моментов
Пусть x1,…,xn – выборка наблюдений случайной величины X, имеющей распределение FX(x, θ) с вектором неизвестных параметров . Предположим, что для этого распределения могут быть рассчитаны начальные и центральные моменты некоторых порядков r. Эти моменты являются функциями неизвестных параметров θ1,…,θk. С другой стороны, для выборки могут быть рассчитаны выборочные начальные и центральные моменты тех же порядков r.
Метод моментов состоит нахождении такого вектора параметров θ, при котором теоретические моменты равны выборочным моментам, т.е. в разрешении системы уравнений вида:
Число уравнений в системе (1) равно числу неизвестных параметров k. Для получения оценок по методу моментов, вообще говоря, могут быть выбраны любые моменты произвольных порядков, однако, как правило, на практике используют лишь моменты низших порядков.
Все оценки, рассчитанные по методу моментов, являются состоятельными, однако их несмещённость и эффективность, так же, как и в случае метода подстановки, не гарантированы.
Точечные оценки, полученные по методу моментов, называются ММ-оценками.
3. Метод максимального правдоподобия
Метод максимального правдоподобия (maximum likelihood estimation, MLE) является наиболее популярным методом оценивания неизвестных параметров распределений.
Пусть x1,…,xn – выборка наблюдений случайной величины X, имеющей распределение FX(x, θ) с вектором неизвестных параметров . Функцией правдоподобия выборки x1,…, xn из генеральной совокупности X называется совместная функция плотности распределения случайного вектора при условии, что его реализация :
.
Учитывая, что компоненты X1,…, Xn случайной выборки, реализациями которых являются выборочные значения x 1,…,xn, независимы, многомерная функция плотности есть произведение одномерных функций плотностей:
В (2) учтено, что все компоненты X1,…, Xn имеют одинаковое распределение, совпадающее с распределением генеральной совокупности X.
Функция правдоподобия выборки x1,…, xn является функцией только вектора неизвестных параметров θ.
Аналогично определяется функция правдоподобия для случая дискретной генеральной совокупности с распределением вероятностей P(x, θ), :
.
Метод максимального правдоподобия состоит в том, что в качестве оценки вектора неизвестных параметров принимается вектор , доставляющий максимум функции правдоподобия, т.е.
.
Иными словами, метод максимального правдоподобия состоит в отыскании такого вектора параметров , при котором данная реализация x1,…, xn случайной выборки X1,…,Xn была бы наиболее вероятной.
Запишем необходимое условие экстремума функции правдоподобия:
Это система k уравнений с k неизвестными θ1,…,θk, решая которую, получаем оценки неизвестных параметров распределения.
На практике бывает удобно вместо системы уравнений (3) составить систему уравнений
,
которая имеет те же решения. Функция называется логарифмической функцией правдоподобия.
Все оценки, рассчитанные по методу максимального правдоподобия, являются состоятельными и, по крайней мере, асимптотически несмещёнными и асимптотически эффективными. Если для неизвестного параметра существует эффективная оценка, то метод максимального правдоподобия даёт именно эту оценку.
Точечные оценки, полученные по методу максимального правдоподобия, называются МП-оценками.
Точечные оценки математического ожидания и дисперсии
1. Оценки математического ожидания
1) Оптимальной оценкой математического ожидания является выборочное среднее
.
Оценка является несмещённой, состоятельной, эффективной.
2) На практике нередко возникает необходимость быстрой оценки математического ожидания. Такой оценкой может быть
.
Оценка является состоятельной и, по крайней мере, асимптотически несмещённой и асимптотически эффективной.
3) В качестве оценки математического ожидания симметричного распределения может быть использована выборочная медиана
.
Можно показать, что при больших объёмах выборки распределение статистики аппроксимируется нормальным распределением . Таким образом, эффективность выборочной медианы как оценки математического ожидания равна
.
Оценка является состоятельной, несмещённой, но неэффективной.
4) Рассмотрим две выборки объёмов n1 и n2 из одной генеральной совокупности. Пусть и – выборочные средние. Тогда агрегированная оценка математического ожидания генеральной совокупности:
является несмещённой, состоятельной, эффективной.
2. Оценки дисперсии
1) Оптимальной оценкой дисперсии является исправленная выборочная дисперсия:
.
Оценка является несмещённой, состоятельной, эффективной.
2) Выборочная дисперсия
.
Оценка является асимптотически несмещённой, состоятельной, асимптотически эффективной.
3) На практике нередко возникает необходимость быстрой оценки дисперсии. Такой оценкой может быть
.
Оценка является грубой, для большинства распределений смещённой и неэффективной.
4) В случае если известно математическое ожидание m генеральной совокупности, оптимальной оценкой дисперсии является статистика:
.
Оценка является несмещённой, состоятельной, эффективной.
5) Рассмотрим две выборки объёмов n1 и n2 из одной генеральной совокупности. Пусть и – исправленные выборочные дисперсии. Тогда агрегированная оценка дисперсии генеральной совокупности
является несмещённой, состоятельной, эффективной.
Интервальные оценки
Понятие доверительного интервала
Точечная оценка неизвестного параметра θ является случайной величиной, определяемой как некоторая функция случайной выборки X1,…,Xn. Это означает, что для каждой новой реализации x1,…,xn этой выборки точечная оценка каждый раз будет иметь новое значение. Использование точечных оценок не даёт ответа на вопрос, насколько для данной выборки x1,…, xn рассчитанная реализация точечной оценки близка к значению оцениваемого параметра θ. Ответ на этот вопрос могут дать интервальные оценки. Интервальная оценка позволяет получить вероятностную характеристику точности оценивания неизвестного параметра θ.
Пусть X1,…,Xn – случайная выборка объёма n из генеральной совокупности X с функцией распределения FX(x; θ), зависящей от параметра θ, значение которого неизвестно. Доверительным интервалом для параметра θ называется интервал (θ1; θ2), содержащий (накрывающий) истинное значение θ с заданной вероятностью γ, т.е.
где и – некоторые статистики. Вероятность γ называется доверительной вероятностью, а вероятность – уровнем значимости. Доверительный интервал с доверительной вероятностью γ называют также γ-доверительным интервалом, или γ-доверительной интервальной оценкой параметра θ. Статистики θ1 и θ2 называются нижней и верхней границами доверительного интервала соответственно.
Доверительный интервал – это интервал со случайными границами θ1 и θ2. Для каждой новой реализации x1,…,xn случайной выборки X1,…,Xn эти случайные величины, а следовательно, и случайные величины θ1, θ2 будут принимать новые значения. Однако, согласно определению, для данной реализации x1,…,xn рассчитанная реализация доверительного интервала (θ1; θ2) накроет истинное значение неизвестного параметра θ с заданной вероятностью γ. Это означает, что доля реализаций случайной выборки X1,…,Xn, для которых доверительный интервал (θ1; θ2) накроет θ, в среднем равна доверительной вероятности γ.
Пример. Исследуется качество партии выпускаемых предприятием изделий. Пусть θ – доля бракованных изделий в партии, которую оценивают независимо друг от друга в N различных лабораториях по результатам обследования нескольких случайно выбранных деталей из партии. Иначе говоря, долю бракованных изделий в партии в каждой лаборатории оценивают по «своей» выборке деталей из партии, и в каждой лаборатории получают свои значения верхней и нижней границ γ-доверительного интервала.
Возможны случаи, когда γ-доверительный интервал не накрывает истинного значения θ. Если M – число таких случаев, то их доля будет стремиться к уровню значимости α при увеличении N, т.е. при .
Ширина доверительного интервала, характеризующая точность интервального оценивания, зависит от объёма выборки n и доверительной вероятности γ: при увеличении объёма выборки ширина доверительного интервала уменьшается. Причина этого состоит в том, что в выборке большего объёма содержится больше информации об оцениваемом параметре, что позволяет более точно определить область, в которой он находится. При увеличении доверительной вероятности предъявляется более «жёсткое» требование к вероятности нахождения неизвестного параметра внутри доверительного интервала, вследствие чего его ширина увеличивается.
Границы доверительного интервала θ1 и θ2 могут быть выбраны множеством способов. Единственное требование, предъявляемое к этим статистикам – это выполнение условия (1). Однако на практике, как правило, эти статистики выбирают, исходя из некоторых соображений симметрии, которые будут рассмотрены далее.
Иногда требуется оценить параметр θ только снизу или только сверху. При этом, если
,
то доверительный интервал (θ1; ∞) называется правосторонним, а статистика – односторонней нижней границей доверительного интервала.
Если же
,
то доверительный интервал (-∞; θ2) называется левосторонним, а статистика – односторонней верхней границей доверительного интервала.
Метод построения доверительных интервалов
Пусть X1,…,Xn – случайная выборка объёма n из генеральной совокупности X с функцией распределения FX(x; θ), зависящей от параметра θ, значение которого неизвестно. Наиболее простым и популярным методом построения доверительного интервала (θ1; θ2) для неизвестного параметра θ является метод, основанный на использовании так называемой центральной статистики.
Центральной статистикой случайной выборки X1,…,Xn называется любая статистика , зависящая от неизвестного параметра θ, удовлетворяющая следующим свойствам:
1. закон распределения FZ(z) статистики Z известен и не зависит от θ;
2. статистика Z непрерывна и строго монотонна по θ.
Из определения квантиля следует, что для любой случайной величины, в том числе, и для статистики справедливо равенство:
где и – квантили случайной величины Z на уровнях α/2 и (1–α/2) соответственно.
При построении односторонних доверительных интервалов рассматриваются другие равенства:
Задача нахождения доверительного интервала состоит в разрешении неравенства, стоящего под знаком вероятности в выражении (1) (или выражениях (2), (3)), относительно неизвестного параметра θ. В результате получим эквивалентное выражение:
,
из которого следует, что интервал является доверительным.
Таким образом, алгоритм построения доверительного интервала для неизвестного параметра θ на основе случайной выборки X1,…,Xn состоит в следующем.
1. Выбор центральной статистики и определение её закона распределения FZ(z). Знание закона распределения необходимо для расчёта квантилей и (или zα и z1-α).
2. Разрешение неравенства под знаком вероятности в выражении (1) (или выражениях (2), (3)) относительно θ.
Очевидно, что для случайной выборки X1,…, Xn в общем случае может быть построено бесконечно много центральных статистик Z. Возникает вопрос, какую центральную статистику выбрать, чтобы полученный с её помощью доверительный интервал был бы наиболее узким, а следовательно, наиболее точным, при фиксированной доверительной вероятности ?
Как правило, центральные статистики связывают с некоторой точечной оценкой неизвестного параметра θ. Чем меньше дисперсия точечной оценки , тем меньшей дисперсией будет обладать и центральная статистика Z, построенная на основе . А для случайной величины с меньшей дисперсией интервал будет ýже при прочих равных условиях. Учитывая монотонность зависимости центральной статистики Z от параметра θ, заключаем, что чем ýже интервал , тем ýже доверительный интервал (θ1; θ2). Таким образом, из вышесказанного следует, что центральную статистику целесообразно выбирать связанной с эффективной оценкой неизвестного параметра θ.
Законы распределения некоторых статистик нормальной выборки
Пусть X1,…,Xn – случайная выборка объёма n из нормально распределённой генеральной совокупности N(m, σ). Для вывода выражений для доверительных интервалов найдём законы распределения некоторых статистик, которые могут быть выбраны как центральные.
1. Статистика (среднее арифметическое).
В силу композиционной устойчивости нормального распределения статистика имеет распределение .
2. Статистика (стандартизованное среднее арифметическое при известной дисперсии).
Статистика имеет распределение .
3. Статистика (оценка дисперсии при известном математическом ожидании).
Для вывода закона распределения домножим и разделим каждое слагаемое на σ2:
,
где случайные величины Ui, , независимы и имеют стандартизованное нормальное распределение N(0, 1). По определению закона распределения хи-квадрат, случайная величина . Далее будем записывать, что статистика .
4. Статистика (оценка дисперсии при неизвестном математическом ожидании).
Теорема Фишера. Пусть X1,…, Xn – независимые случайные величины, имеющие нормальное распределение N(m, σ). Тогда случайные величины и S2 независимы, и случайная величина .
5. Статистика (стандартизованное среднее арифметическое при неизвестной дисперсии).
Применяя выражение для статистики U, запишем
.
По определению закона распределения Стьюдента статистика .
Запишем теперь законы распределения некоторых статистик, связанных с двумя случайными выборками. Пусть и – случайные выборки объёмов n1 и n2 из нормально распределённых генеральных совокупностей N(m1, σ1) и N(m2, σ2) соответственно.
6. Статистика (агрегированное среднее).
Средние арифметические выборок имеют нормальные распределения и . В связи с композиционной устойчивостью нормального распределения статистика также будет иметь нормальное распределение. Применяя свойства операторов математического ожидания и дисперсии, находим его параметры:
,
.
7. Статистика (стандартизованное агрегированное среднее арифметическое при известной дисперсии).
Статистика имеет распределение .
8. Статистика (агрегированная оценка дисперсии при известном математическом ожидании).
Если , то статистика имеет распределение .
9. Статистика (агрегированная оценка дисперсии при неизвестном математическом ожидании).
Если , то статистика имеет распределение .
10. Статистика (разность средних при известных дисперсиях).
В связи с композиционной устойчивостью нормального распределения статистика Δ будет иметь нормальное распределение. Применяя свойства операторов математического ожидания и дисперсии, находим его параметры:
,
.
11. Статистика (стандартизованная разность средних при известных дисперсиях).
Статистика имеет распределение .
В частном случае, если , то
.
12. Статистика (стандартизованная разность средних при неизвестных дисперсиях).
Если , то
.
По определению закона распределения Стьюдента статистика .
13. Статистика (стандартизованное отношение дисперсий при известном математическом ожидании).
Применяя выражение для статистики , запишем:
.
По определению закона распределения Фишера статистика .
14. Статистика (стандартизованное отношение дисперсий при не известном математическом ожидании).
Применяя выражение для статистики (см. п.4), запишем:
.
По определению закона распределения Фишера статистика .
Построение интервальных оценок параметров нормального распределения
Пусть X1,…,Xn – случайная выборка объёма n из нормально распределённой генеральной совокупности N(m, σ). Рассмотрим варианты построения доверительных интервалов для математического ожидания m и дисперсии σ2.
1. Доверительный интервал для математического ожидания m при известной дисперсии σ2.
В качестве центральной статистики выберем стандартизованное среднее . При таком выборе центральной статистики доверительный интервал для математического ожидания на уровне значимости α имеет вид:
.
2. Доверительный интервал для математического ожидания m при неизвестной дисперсии σ2.
В качестве центральной статистики выберем стандартизованное среднее . Запишем тождество (1*) для статистики T:
,
где и – квантили распределения Стьюдента с n–1 степенями свободы на уровнях α/2 и 1–α/2 соответственно.
Разрешая неравенство под знаком вероятности относительно m и учитывая симметричность распределения Стьюдента, получим:
,
откуда следует, что интервал
является доверительным для m на уровне значимости α.
3. Доверительный интервал для дисперсии σ2 при известном математическом ожидании m.
В качестве центральной статистики выберем статистику . Запишем тождество (1*):
,
где и – квантили распределения хи-квадрат с n степенями свободы на уровнях α/2 и 1–α/2 соответственно.
Разрешая неравенство под знаком вероятности относительно σ2, получим:
,
откуда следует, что интервал является доверительным для σ2 на уровне значимости α.
4. Доверительный интервал для дисперсии σ2 при неизвестном математическом ожидании m.
В качестве центральной статистики выберем статистику . Запишем тождество (1*):
,
где и – квантили распределения хи-квадрат с n-1 степенями свободы на уровнях α/2 и 1–α/2 соответственно.
Разрешая неравенство под знаком вероятности относительно σ2, получим:
,
откуда следует, что интервал является доверительным для σ2 на уровне значимости α.
Рассмотрим теперь варианты построения доверительных интервалов, связанных с двумя выборками. Пусть и – случайные выборки объёмов n1 и n2 из нормально распределённых генеральных совокупностей N(m1, σ1) и N(m2, σ2) соответственно.
5. Доверительный интервал для разности математических ожиданий m1 – m2 при известных дисперсиях и .
В качестве центральной статистики выберем стандартизованную разность средних при известных дисперсиях:
.
Запишем тождество (1*):
,
где и – квантили стандартизованного нормального распределения на уровнях α/2 и 1–α/2 соответственно.
Разрешая неравенство под знаком вероятности относительно m1 – m2 и учитывая симметричность нормального распределения, получим:
,
откуда следует, что интервал
является доверительным для m1 – m2 на уровне значимости α.
6. Доверительный интервал для разности математических ожиданий m1 – m2 при неизвестных равных дисперсиях .
В качестве центральной статистики выберем стандартизованную разность средних при неизвестных равных дисперсиях
.
Запишем тождество (1*):
,
где и – квантили распределения Стьюдента с n1+n2–2 степенями свободы на уровнях α/2 и 1–α/2 соответственно.
Разрешая неравенство под знаком вероятности относительно m1 – m2 и учитывая симметричность распределения Стьюдента, получим:
,
откуда следует, что интервал
;
является доверительным для m1 – m2 на уровне значимости α.
7. Доверительный интервал для отношения дисперсий при известных математических ожиданиях m1 и m2.
В качестве центральной статистики выберем статистику .
Запишем тождество (1*):
,
где и – квантили распределения Фишера с n1 и n2 степенями свободы в числителе и в знаменателе на уровнях α/2 и 1–α/2 соответственно.
Разрешая неравенство под знаком вероятности относительно и учитывая, что , получим:
,
откуда следует, что интервал
является доверительным для на уровне значимости α.
8. Доверительный интервал для отношения дисперсий при неизвестных математических ожиданиях m1 и m2.
В качестве центральной статистики выберем статистику .
Запишем тождество (1*):
,
где и – квантили распределения Фишера с n1–1 и n2–1 степенями свободы в числителе и в знаменателе на уровнях α/2 и 1–α/2 соответственно.
Разрешая неравенство под знаком вероятности относительно и учитывая, что , получим:
,
откуда следует, что интервал
является доверительным для на уровне значимости α.
Интервальная оценка вероятности «успеха» в схеме Бернулли
Пусть проводится серия из n испытаний по схеме Бернулли, и Xi, , – исход i-го испытания (Xi = 1, если «успех», и Xi = 0, если «отказ»). По данным случайной выборки X1,…,Xn построим доверительный интервал для вероятности p успеха в каждом отдельном испытании.
Рассмотрим число «успехов» в серии из n испытаний, т.е. введём случайную величину
,
которая имеет биномиальное распределение . Математическое ожидание и дисперсия .
В соответствии с предельной теоремой Муавра-Лапласа при больших объёмах n случайной выборки статистика K имеет закон распределения, близкий к нормальному: .
Для построения доверительного интервала введём центральную статистику:
.
Статистика представляет собой стандартизованное число «успехов» в серии из n испытаний и при больших n имеет распределение, близкое к N(0, 1).
Запишем тождество (1*) для статистики U:
,
где и – квантили стандартизованного нормального распределения на уровнях α/2 и 1–α/2 соответственно. Преобразуя неравенство под знаком вероятности, запишем:
.
Это выражение ещё не даёт интервальной оценки параметра p, так как левая и правая части неравенства под знаком вероятности содержат этот параметр. На практике в указанные части неравенства подставляют вместо неизвестного точного значения p его эффективную оценку . В результате получают следующий интервал для вероятности p:
,
являющийся доверительным на уровне значимости α.
Указанные границы доверительного интервала являются приближёнными и могут использоваться лишь при достаточно больших объёмах наблюдений n.
Пусть теперь проводятся две серии испытаний по схеме Бернулли, и требуется построить доверительный интервал для разности вероятностей «успехов» p1 и p2 в этих сериях. Случайные величины и , означающие число «успехов» в первой и второй сериях соответственно, имеют биномиальные распределения , , где n1 и n2 – число испытаний в сериях.
В соответствии с предельной теоремой Муавра-Лапласа при больших объёмах n1 и n2 случайных выборок статистики K1 и K2 имеют законы распределения, близкие к нормальному: , . Перейдём от числа «успехов» K1 и K2 к относительным частотам «успехов» H1 и H2:
,
.
В силу композиционной устойчивости нормального распределения, разность относительных частот также будет иметь нормальное распределение:
.
Для построения доверительного интервала введём центральную статистику:
.
Статистика представляет собой стандартизованную разность числа «успехов» в двух сериях испытаний и при больших n1 и n2 имеет распределение, близкое к N(0, 1).
Запишем тождество (1*) для статистики U:
,
где и – квантили стандартизованного нормального распределения на уровнях α/2 и 1–α/2 соответственно. Преобразуя неравенство под знаком вероятности, запишем:
.
Это выражение ещё не даёт интервальной оценки разности вероятностей p1 – p2, так как левая и правая части неравенства под знаком вероятности содержат эти параметры. На практике в указанные части неравенства подставляют вместо неизвестных точных значений p1 и p2 их эффективные оценки и . В результате получают следующий интервал для разности вероятностей p1 – p 2:
,
являющийся доверительным на уровне значимости α.
Указанные границы доверительного интервала являются приближёнными и могут использоваться лишь при достаточно больших объёмах наблюдений n1 и n2.
Проверка статистических гипотез
Основные понятия и определения
В практических задачах часто требуется проверить то или иное предположение относительно каких-нибудь свойств закона распределения наблюдаемой случайной величины X. Для проверки этого предположения исследователь проводит эксперимент, в результате которого получает реализацию x1,...,xn случайной выборки X1,...,Xn из генеральной совокупности X. По этим данным ему нужно дать ответ на вопрос: согласуется ли его гипотеза с результатами эксперимента или нет? Другими словами, исследователю нужно решить, можно ли принять выдвинутую гипотезу или её нужно отклонить как противоречащую результатам эксперимента.
Любое предположение относительно параметров или закона распределения наблюдаемой случайной величины (или нескольких величин) называется статистической гипотезой. Проверяемую статистическую гипотезу также называют основной, или нулевой, статистической гипотезой и, как правило, обозначают H0.
Наряду с проверяемой статистической гипотезой H0 выдвигают также конкурирующую гипотезу, противоречащую H0. Конкурирующая гипотеза называется альтернативной и, как правило, обозначается H1 или H’. Если в результате статистического анализа делается вывод, что основная гипотеза H0 должна быть отвергнута, то решение принимается в пользу альтернативной гипотезы H’. В простейшем случае альтернативная гипотеза – это отрицание основной гипотезы.
Статистическая гипотеза H0 называется простой, если она однозначно определяет параметр или распределение наблюдаемой случайной величины X. В противном случае гипотеза H0 называется сложной.
Если статистическая гипотеза H0 представляет собой утверждение о некотором параметре q известного распределения случайной величины X, то гипотеза называется параметрической. В противном случае гипотеза называется непараметрической.
Статистическое решение, т.е. решение о принятии или отклонении основной гипотезы H0, проводится в соответствии с некоторым критерием.
Статистическим критерием, или решающим правилом, при проверке статистической гипотезы H0 называется правило, в соответствии с которым гипотеза H0 принимается или отвергается.
Статистическая гипотеза – это всегда утверждение о свойствах наблюдаемой генеральной совокупности, а задача проверки статистической гипотезы состоит в проверке соответствия результатов эксперимента x1,...,xn выдвинутой гипотезе. Иными словами, задача проверки статистической гипотезы состоит в ответе на вопрос: могло ли случиться так, что выборка x1,..., xn была получена из генеральной совокупности с указанными в гипотезе свойствами?
Как правило, статистический критерий связывают с некоторой статистикой Z, являющейся функцией случайной выборки X1,...,Xn. Эта статистика служит мерой, насколько наблюдаемые выборочные значения могли быть получены из генеральной совокупности с указанными в основной гипотезе свойствами. Вопрос о том, какую статистику Z следует взять для проверки той или иной статистической гипотезы, не имеет однозначного ответа. Это может быть любая статистика, удовлетворяющая следующим требованиям:
1) закон распределения FZ(z | H0) при условии истинности основной гипотезы H0 должен быть известен;
2) закон распределения должен быть чувствителен к факту справедливости основной или альтернативной гипотезы, т.е. законы распределения FZ(z | H0) и FZ(z | H’) должны существенно различаться.
Для реализации x1,...,xn случайной выборки X1,...,Xn, статистика Z примет реализацию z. Предположим, что гипотеза H0 верна. В связи с тем, что закон распределения статистики Z при условии истинности основной гипотезы H0 известен, то возможно рассчитать вероятность её попадания в некоторую окрестность точки z. Если эта вероятность высока, это означает, что ничто не противоречит предположению об истинности гипотезы H0. Если же эта вероятность мала или близка к нулю, то это может означать один из двух вариантов:
1) в условиях основной гипотезы H0 произошло практически невозможное событие;
2) статистика Z на самом деле имеет некоторый другой закон распределения, отличный от FZ(z | H0), при котором вероятность её попадания в окрестность точки z много больше нуля. Это означает, что предположение об истинности гипотезы H0 сделано неверно.
Статистика , на основе реализации которой выдвигается статистическое решение, называется статистикой критерия (test statistics). Реализация статистики критерия , рассчитанная для выборки x1,...,xn, называется выборочным значением статистики критерия.
Проверка статистических гипотез основывается на принципе, в соответствии с которым маловероятные события относительно статистики критерия Z считаются невозможными. В соответствии с этим принципом, если вероятность попадания статистики критерия Z в окрестность рассчитанного выборочного значения z мала, то должен выбираться вариант 2), т.е. основная гипотеза H0 отклоняется.
Область Ω0 наиболее вероятных значений статистики критерия Z, при попадании выборочных значений z в которую основная гипотеза H0 принимается, называется областью допустимых значений статистики критерия Z.
Область Ω’ маловероятных значений статистики критерия Z, при попадании выборочных значений z которую основная гипотеза H0 отклоняется, называется критической областью значений статистики критерия Z. Множество должно являться множеством всех возможных значений статистики критерия Z.
Из определений области допустимых значений и критической области следует статистический критерий проверки гипотезы H0: если выборочное значение статистики критерия , то основная гипотеза H0 принимается, если выборочное значение статистики критерия , то основная гипотеза H0 отвергается.
Пусть для выборки x1,...,xn статистика критерия Z приняла выборочное значение z, лежащее в критической области Ω’, т.е. вероятность попадания статистики критерия Z в окрестность которой мала. В соответствии со статистическим критерием основная гипотеза H0 должна быть отвергнута. Однако событие , хоть и с малой вероятностью, но всё же могло произойти в условиях основной гипотезы H0. Если это так, то статистическое решение об отклонении гипотезы H0 будет ошибочным.
С другой стороны, если для выборки x1,...,xn статистика критерия Z приняла выборочное значение z, лежащее в области допустимых значений Ω0, это могло случиться как в условиях основной гипотезы H0 (с высокой вероятностью), так и, возможно, в условиях альтернативной гипотезы H’ (с низкой вероятностью). В соответствии со статистическим критерием основная гипотеза H0 принимается. Если же событие на самом деле произошло в условиях альтернативной гипотезы H’, то статистическое решение о принятии гипотезы H0 также будет ошибочным. В обоих случаях говорят об ошибках принятия статистического решения.
Ошибкой 1-го рода при принятии статистического решения называется событие, состоящее в том, что основная гипотеза H0 отвергается, в то время как она верна.
Ошибкой 2-го рода при принятии статистического решения называется событие, состоящее в том, что основная гипотеза H0 принимается, в то время как верна альтернативная гипотеза H’.
Уровнем значимости α при проверке статистической гипотезы называется вероятность ошибки первого рода:
.
Вероятность β ошибки второго рода:
.
Ясно, что с уменьшением вероятности ошибки первого рода возрастает вероятность ошибки второго рода и наоборот. Это означает, что при выборе критической области и области допустимых значений статистики критерия должен достигаться определённый компромисс.
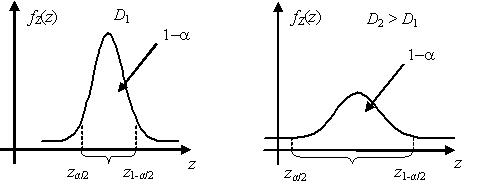
Проиллюстрируем сказанное на примере. Пусть основная и альтернативная гипотезы H0 и H’ являются простыми. Пусть статистики критерия Z при условии истинности основной гипотезы H0 имеет нормальное распределение , а при условии истинности H’ – распределение .
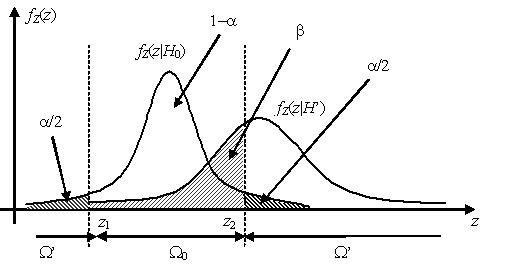
У качестве критической области Ω’ выбраны хвосты распределения , площадь каждого из которых равна α/2. Вероятность попадания статистики критерия Z, имеющей распределение , в критическую область, таким образом, равна вероятности ошибки первого рода α. Вероятность ошибки второго рода β равна площади под графиком функции плотности распределения внутри области допустимых значений Ω0. Из графиков видно, что уменьшая ширину области допустимых значений, площадь a будет увеличиваться, в то время как площадь β – уменьшаться, и наоборот.
Точки на оси значений статистики критерия z, разделяющие область допустимых значений Ω0 и критическую область Ω’, называются критическими точками. На рисунке выше это точки z1 и z2, являющиеся квантилями распределения на уровнях α/2 и 1 – α/2 соответственно.
В случае если основная и альтернативная гипотезы H0 и H’ являются простыми, величина μ = 1 – β называется мощностью критерия.
Очевидно, что при заданном значении вероятности ошибки первого рода a выбор критической области Ω’ может быть сделан неоднозначно. Единственное требование, предъявляемое к критической области, состоит в том, что площадь под графиком известного распределения статистики критерия в критической области должна быть равна α. Однако соответствующие различным критическим областям критерии будут иметь, вообще говоря, различные вероятности β ошибок второго рода.
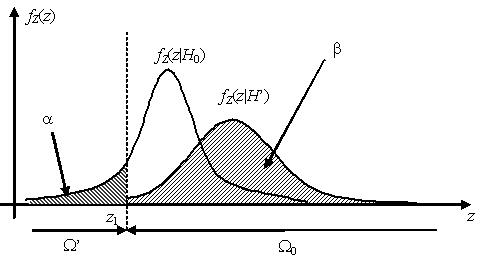
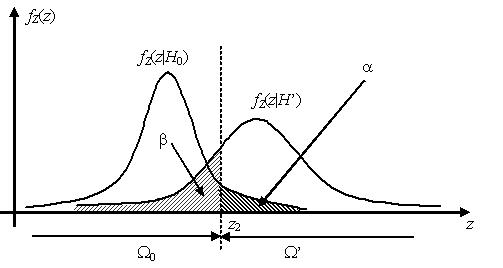
Наилучшей критической областью (НКО) называют критическую область, которая при заданном уровне значимости a обеспечивает минимальную вероятность β ошибки второго рода. Критерий, использующий наилучшую критическую область, имеет максимальную мощность.
Если альтернативная гипотеза является сложной, т.е. не определяет однозначно функцию распределения FX(x) генеральной совокупности X, а следовательно, и функцию распределения статистики критерия , а определяет её с точностью до значения некоторого параметра θ, то вводят функцию мощности критерия μ(θ) как функцию параметра θ. Значение функции мощности критерия μ(θ) в точке θ определяется как
,
где β(θ) – вероятность ошибки второго рода при условии, что неизвестный параметр принял значение θ, θ∈Θ, где Θ – область возможных значений параметра θ.
Функция мощности имеет важное значение в задачах, связанных с оценкой необходимого объёма выборки для обеспечения требуемой вероятности ошибки второго рода принятия статистического решения при заданной вероятности ошибки первого рода.
Алгоритм проверки статистических гипотез
Далее будем рассматривать лишь случай простой основной статистической гипотезы. Алгоритм проверки любой простой гипотезы включает следующие этапы.
1) Сформулировать проверяемую гипотезу H0 и альтернативную гипотезу H’. Гипотезы формулируются, исходя из условия задачи или особенностей рассматриваемой проблемной области.
2) Выбрать уровень значимости α, на котором будет сделано статистическое решение. Уровень значимости выбирается исследователем как допустимая вероятность ошибки первого рода при принятии статистического решения. Обычно, уровень значимости выбирается небольшим, например, α = 0,1 или α = 0,01, однако, следует помнить, что выбор слишком малого уровня значимости приведёт к увеличению вероятности ошибки второго рода при принятии статистического решения.
3) Выбрать статистику критерия Z для проверки гипотезы H0. Для большинства встречающихся на практике статистических гипотез H0 выражение для статистики критерия Z, обеспечивающей минимальное или близкое к минимальному значение вероятности ошибки второго рода при фиксированном уровне значимости, известно. От исследователя, как правило, не требуется придумывать оригинальное выражение для используемой статистики критерия.
4) Найти закон распределения выбранной статистики критерия Z при условии истинности основной гипотезы H0. Законы распределения большинства используемых на практике статистик критерия также известны.
5) Построить область допустимых значений Ω0 и критическую область Ω’. Критическая область Ω’ зависит от вида статистики критерия Z, альтернативной гипотезы H’ и уровня значимости α.
Простая основная параметрическая гипотеза имеет вид , где θ – неизвестный параметр генеральной совокупности, θ0 – некоторая константа из области возможных значений параметра θ. Для такой основной гипотезы возможны следующие варианты формулировок альтернативных гипотез:
а) ;
б) ;
в) .
Как правило, оптимальная критическая область – это область маловероятных значений статистики критерия в хвостах распределения. Если критическая область расположена в левом хвосте распределения , то такая критическая область называется левосторонней, если в правом хвосте – то правосторонней, если в обоих хвостах – то двусторонней. В случае двусторонней критической области площади каждого из хвостов, как правило, выбираются равными.
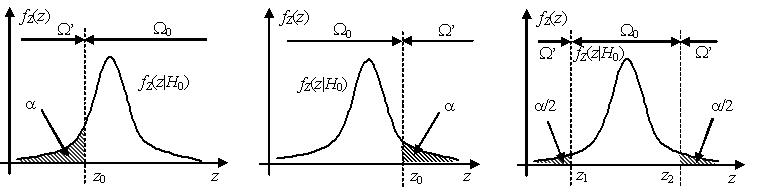
Уровень значимости α определяет ширину критической области.
6) Вычислить выборочное значение статистики критерия z на основе имеющихся выборочных наблюдений из генеральной совокупности.
7) Принять статистическое решение, используя решающее правило: если выборочное значение статистики критерия , то основная гипотеза H0 принимается, если выборочное значение статистики критерия , то основная гипотеза H0 отвергается в пользу альтернативной гипотезы H’.
Иногда при использовании статистических пакетов для проверки гипотез процедура статистического анализа не возвращает в явном виде выборочное значение z статистики критерия Z. В этом случае статистическое решение принимается на основе так называемого значения p-value.
Если альтернативная гипотеза имеет вид , то значение p-value – это площадь под графиком функции плотности распределения статистики критерия, расположенная левее / правее выборочного значения статистики критерия z:
$H':\theta
Иными словами, p-value – это вероятность того, что статистика критерия Z примет более «экстремальные» значения в левом / правом хвосте критической области, чем рассчитанное по выборке выборочное значение z.
Если альтернативная гипотеза имеет вид , то p-value рассчитывается по следующей формуле:
.
В этом случае p-value – это вероятность того, что статистика критерия Z примет более «экстремальные» значения, чем z, в любом из хвостов двусторонней критической области.
Если значение p-value мало, это свидетельствует о том, что выборочное значение статистики критерия z уже приняло довольно «экстремальное» значение, что может говорить о противоречии выборочных данных основной гипотезе. Если значение p‑value велико, то оснований отвергать основную гипотезу нет.
При использовании значения p-value критерий проверки статистической гипотезы формулируется следующим образом: если значение p-value больше уровня значимости a, то основная гипотеза H0 принимается, если значение p‑value меньше уровня значимости a, то основная гипотеза H0 отвергается.
Если основная гипотеза H0 отвергается, то делается вывод, что выборочные наблюдения противоречат основной гипотезе, если же H0 принимается, то выборочные данные могли быть получены из генеральной совокупности со свойствами, указанными в H0, что, впрочем, не означает, что генеральная совокупность в самом деле имеет эти свойства.
Проверка гипотез о параметрах нормально распределённой генеральной совокупности
Пусть x1,…,xn – выборка наблюдений случайной величины X, имеющей нормальное распределение N(m, σ). Ниже приводятся наилучшие по мощности статистики критерия для различных вариантов гипотез относительно параметров m и s. Как правило, эти статистики связаны с эффективными оценками параметров, относительно которых выдвигаются гипотезы.
1) Гипотеза о значении математического ожидания при известной дисперсии (one-sampled z-test).
.
В качестве статистики критерия используется статистика
|
. |
При условии истинности H0 случайная величина
,
следовательно, .
2) Гипотеза о значении математического ожидания при неизвестной дисперсии (one-sample t-test).
В связи с тем, что σ не известно, статистику (1) здесь использовать нельзя. Вместо σ в (1) подставляется оценка S среднеквадратичного отклонения:
,
при этом в условиях истинности гипотезы H0 статистика Z будет иметь распределение Стьюдента с n–1 степенью свободы.
3) Гипотеза о значении дисперсии при известном математическом ожидании (chi-squared test).
.
Эффективной оценкой дисперсии при известном математическом ожидании является статистика . В качестве статистики критерия выберем статистику
.
Очевидно, что при условии истинности H0 статистика
.
4) Гипотеза о значении дисперсии при неизвестном математическом ожидании (chi-squared test).
.
Эффективной оценкой дисперсии при неизвестном математическом ожидании является статистика . В качестве статистики критерия выберем статистику
.
Очевидно, что при условии истинности H0 статистика
.
Запишем теперь статистики критерия для гипотез, связанных с параметрами двух генеральных совокупностей. Пусть и – выборки объёмов n1 и n2 из нормально распределённых генеральных совокупностей N(m1, σ1) и N(m2, σ2) соответственно.
5) Гипотеза о равенстве математических ожиданий при известных дисперсиях (two-sample z-test).
.
Статистики , .
Несложно показать, что при условии истинности H0 статистика
имеет стандартизованное нормальное распределение N(0; 1).
6) Гипотеза о равенстве дисперсий при известных математических ожиданиях (two-sample F-test).
.
В качестве статистики критерия используется отношение оценок дисперсий при известных математических ожиданиях
,
которое при условии истинности H0 распределено по закону Фишера .
7) Гипотеза о равенстве дисперсий при неизвестных математических ожиданиях (two-sample F-test).
.
В качестве статистики критерия используется отношение оценок дисперсий при неизвестных математических ожиданиях
,
которое при условии истинности H0 распределено по закону Фишера .
8) Гипотеза о равенстве математических ожиданий при неизвестных дисперсиях (two-sample unpooled t-test).
.
а) Дисперсии генеральных совокупностей равны (это может быть известно априорно, исходя из условия задачи, или в случае, если гипотеза при неизвестных математических ожиданиях принимается).
Объединённая оценка дисперсии σ2 по двум выборкам имеет вид:
.
При условии истинности H0 статистика S2 имеет распределение
.
Несложно показать, что статистика
при условии истинности H0 имеет распределение Стьюдента с n1+n2–2 степенями свободы.
б) Оснований считать, что дисперсии генеральных совокупностей равны, нет (Welch’s t-test).
Для каждой из дисперсий вычисляются свои оценки и . Статистика критерия имеет вид:
.
Показано, что при условии истинности H0 статистика Z имеет распределение Стьюдента с числом степеней свободы, равным целой части от величины 1 / k, где
.
Основные статистики критерия при проверке статистических гипотез о параметрах нормально распределённой генеральной совокупности и их законы распределения приведены в табл. 4.1.
Таблица 4.1
Статистики критерия при проверке статистических гипотез о параметрах нормально распределённой генеральной совокупности
Основная гипотеза, H0 |
Мат. ожидание |
Дисперсия |
Статистика критерия, Z |
Закон распределения, |
не изв. |
изв. |
|||
не изв. |
не изв. |
|||
изв. |
не изв. |
|||
не изв. |
не изв. |
|||
не изв. |
изв. |
|||
не изв. |
не изв., равные |
|
||
изв. |
не изв. |
|||
не изв. |
не изв. |
Все приведённые выше выражения для статистик критерия и их законов распределения справедливы, если случайная выборка X1,…, Xn (или выборки и ) получены из нормально распределённой генеральной совокупности. Однако поскольку все статистики основаны на оценках и S2, представляющих собой суммы случайных величин, то согласно центральной предельной теоремы теории вероятностей распределение этих статистик при больших объёмах выборок будет близко нормальному, даже если распределение каждого слагаемого отлично от нормального. В то же время, если генеральная совокупность распределена нормально, то статистика S2 имеет распределение хи-квадрат, которое при больших объёмах выборки также может быть аппроксимировано нормальным распределением. Это означает, что законы распределения статистик критерия остаются справедливыми при больших объёмах выборки в случае распределения генеральной совокупности, отличного от нормального.
В некоторых случаях для проверки параметрических статистических гипотез может быть использован метод доверительных интервалов. Пусть основная гипотеза , альтернативная гипотеза . Если для неизвестного параметра θ может быть построен доверительный интервал (θ1; θ2), то проверка статистической гипотезы H0 сводится к проверке попадания значения θ0 в доверительный интервал (θ1; θ2). Критерий проверки гипотез при использовании метода доверительных интервалов состоит в следующем: если θ0 ∈ (θ1; θ2), то основная гипотеза H0 должна приниматься, в противном случае – отклоняться. Если альтернативная гипотеза H’ имеет вид или , то строится соответствующий односторонний доверительный интервал (–∞; θ2) или (θ1; +∞).
При проверке статистической гипотезы о равенстве математических ожиданий строится доверительный интервал для разности m1 – m2. Если интервал накрывает 0, то основная гипотеза принимается, в противном случае – отклоняется.
При проверке статистической гипотезы о равенстве дисперсий строится доверительный интервал для отношения . Если интервал накрывает 1, то основная гипотеза принимается, в противном случае – отклоняется.
Проверка гипотез о вероятности «успеха» в схеме Бернулли
При статистическом анализе данных, связанных с повторными независимыми испытаниями (схемой Бернулли), обычно рассматривают два вида задач: сравнение вероятности «успеха» p в одном испытании с заданным значением p0 и сравнение вероятности «успеха» в двух сериях испытаний.
Пусть проводится серия из n испытаний по схеме Бернулли и случайная величина K – число «успехов». Тогда K имеет биномиальное распределение . Математическое ожидание и дисперсия . В соответствии с предельной теоремой Муавра-Лапласа при большом числе испытаний n статистика K имеет закон распределения, близкий к нормальному:
.
Частота «успеха» также имеет нормальное распределение .
Для проверки статистической гипотезы (one-proportion z-test)
в качестве статистики критерия используем стандартизованную частоту
,
которая при условии истинности H0 имеет распределение .
Если альтернативная гипотеза , то критическая область для статистики критерия выбирается двусторонней, если или , то левосторонней или правосторонней соответственно.
Пусть теперь проводятся две серии испытаний и требуется проверить гипотезу о равенстве вероятностей «успехов» p1 и p2 в этих сериях (two-proportion z-test):
.
Частота «успеха» в первой серии , во второй серии – , где n1 и n2 – число испытаний в первой и второй сериях соответственно. В силу композиционной устойчивости нормального распределения разность частот также будет иметь нормальное распределение , где
,
.
При условии истинности H0 (т.е. при ) стандартизованная разность частот
имеет стандартизованное нормальное распределение N(0; 1).
Заменяя в знаменателе неизвестную истинную вероятность p на её эффективную оценку – агрегированную частоту
,
получим приближённое выражение для статистики критерия
.
Подчеркнём, что указанная статистика может использоваться лишь при достаточно больших объёмах наблюдений n1 и n2.
Если альтернативная гипотеза , то критическая область для статистики критерия выбирается двусторонней, если или , то левосторонней или правосторонней соответственно.
Критерии согласия и однородность выборок
Проверка гипотез о виде распределения. Критерий Колмогорова
Статистические методы, изложенные в предыдущих главах, опираются на различные априорные допущения о виде исследуемой статистической модели. Например, основные формулы расчёта доверительных интервалов и статистик критерия для проверки статистических гипотез о параметрах распределений выведены в предположениях о нормальности распределения генеральной совокупности и независимости элементов наблюдаемой случайной выборки.
В практических приложениях может возникнуть вопрос о соответствии выборочных наблюдений предполагаемой статистической модели. Эти предположения могут быть сформулированы как статистические гипотезы и проверены с помощью статистических критериев.
Критериями согласия (goodness of fit tests) называют статистические критерии, предназначенные для проверки гипотез о виде распределения наблюдаемой генеральной совокупности. Критерии согласия отвечают на вопрос, насколько хорошо экспериментальные данные согласуются с предполагаемой статистической моделью генеральной совокупности.
Пусть x1,…,xn – выборка наблюдений случайной величины X, имеющей неизвестное распределение FX(x, θ) с вектором неизвестных параметров размерности r. Рассмотрим задачу проверки статистической гипотезы о том, что функция распределения FX(x, θ) совпадает с некоторой известной функцией G(x). Сформулируем основную и альтернативную гипотезы:
,
.
Оценкой неизвестной функции распределения FX(x, θ), рассчитанной по выборке x1,…,xn, является эмпирическая функция распределения . ЭФР выборки x1,…,xn является реализацией случайной эмпирической функции распределения соответствующей случайной выборки X1,…, Xn. В то же время, является состоятельной оценкой функции распределения FX(x, θ). Это означает, что при при каждом фиксированном x случайная величина стремится по вероятности к значению функции распределения FX(x, θ) в точке x. Следовательно, при условии истинности основной гипотезы вероятность того, что рассогласование между и G(x) примет достаточно большие значения, стремится к нулю с ростом объёма выборки n. Меру рассогласования между двумя распределениями можно выбрать многими способами и в зависимости от этого выбора получаем различные статистики критерия для проверки интересующей нас гипотезы.
Критерий Колмогорова (one-sample KS-test), называемый также критерием Колмогорова-Смирнова (A.N. Kolmogorov, N.V. Smirnov, 1933), основан на результатах сравнения ЭФР с предполагаемой функцией распределения G(x) с помощью метрики
Если функции и G(x) близки с точки зрения указанной метрики, то оснований отклонять основную гипотезу H0 нет. Если расхождение между этими функциями велико, то распределение случайной величины X значимо отлично от предполагаемого распределения G(x), следовательно, основная гипотеза H0 должна быть отвергнута в пользу альтернативной.
А.Н. Колмогоровым предложена статистика критерия
,
для которой показано, что при условии истинности основной гипотезы H0 при её закон распределения не зависит от вида функции G(x), причём её функция распределения стремится к предельной (функции распределения Колмогорова):
|
. |
Приближённо полагая при больших n (n > 40), что статистика критерия Zn имеет распределение Колмогорова, для неё может быть рассчитана любая квантиль, используя формулу (2) или таблицу квантилей распределения Колмогорова. Некоторые критические точки распределения Колмогорова и соответствующие им уровни значимости приведены в табл. 5.1.
Таблица 5.1
Таблица квантилей распределения Колмогорова
α |
0,005 |
0,01 |
0,025 |
0,05 |
0,10 |
0,15 |
0,20 |
0,25 |
z1–α |
1,73 |
1,63 |
1,48 |
1,36 |
1,22 |
1,14 |
1,07 |
1,02 |
В случае истинности альтернативной гипотезы H’ рассогласование Dn между ЭФР и G(x) при будет отлично от нуля, причём с увеличением Dn статистика критерия Zn более вероятно будет принимать большие значения. Следовательно, основная гипотеза H0 должна отвергаться в области больших значений Zn, т.е. критическая область должна выбираться правосторонней.
На практике для вычисления рассогласования Dn между ЭФР и G(x) по выборке x1,…,xn удобно использовать формулу
,
которую также можно записать в виде
,
где – вариационный ряд выборки.
Если требуется проверить принадлежность функции распределения FX(x, θ) заданному параметрическому множеству распределений G(x, θ), θ∈Θ, то проверяется согласие эмпирической функции распределения лишь с максимально правдоподобным для данной выборки распределением , где – МП-оценка параметра θ.
Критерий "омега-квадрат"
Из вида метрики Колмогорова (1*) следует, что она хорошо различает функции распределения и G(x), отличающиеся друг от друга достаточно сильно пусть даже в одной единственной точке x. Если же отличается от G(x) на довольно широком интервале (или на всей числовой оси), но везде не очень сильно, то величина Dn будет невелика, и критерий Колмогорова может ложно принять основную гипотезу H0, в то время как на самом деле распределения FX(x, θ) и G(x) различны. Этот факт свидетельствует о высокой вероятности ошибки второго рода при проверке статистической гипотезы о равенстве распределений, что делает критерий Колмогорова маломощным.
Этот недостаток критерия Колмогорова может быть устранён при использовании другой метрики для расчёта рассогласования между двумя распределениями, называемой метрикой «омега-квадрат», – в непрерывном случае:
,
в дискретном случае:
Статистика критерия, основанная на данной метрике, называется статистикой Крамера-Мизеса (Harald Cramer, Richard Edler von Mises, 1930), или статистикой «омега-квадрат»:
,
для которой показано, что при условии истинности основной гипотезы H0 при её закон распределения не зависит от вида функции G(x) и стремится к распределению «омега-квадрат».
Приближённо полагая при больших n (n > 40), что , для статистики критерия может быть рассчитан любой квантиль, используя таблицу. Некоторые критические точки распределения «омега-квадрат» и соответствующие им уровни значимости приведены в табл. 5.2.
Таблица 5.2
Таблица квантилей распределения «омега-квадрат»
α |
0,005 |
0,01 |
0,025 |
0,05 |
0,10 |
0,15 |
0,20 |
0,25 |
z1–α |
0,87 |
0,75 |
0,58 |
0,46 |
0,35 |
0,28 |
0,24 |
0,21 |
Аналогично критерию Колмогорова, в критерии «омега-квадрат» критическая область выбирается правосторонней.
На практике для вычисления рассогласования между ЭФР и G(x) по выборке x1,…,xn удобно использовать формулу
где – вариационный ряд выборки.
Критерий "хи-квадрат"
Пусть x1,…,xn – выборка наблюдений случайной величины X, имеющей неизвестное распределение FX(x, θ) с вектором неизвестных параметров размерности r. Наряду с критерием Колмогорова и критерием «омега-квадрат» для проверки гипотезы о совпадении функции распределения FX(x, θ) с некоторой известной функцией G(x):
,
;
может быть также использован критерий Пирсона.
Критерий Пирсона (Karl Pearson, 1900), или критерий «хи-квадрат» (Pearson’s chi-squared test), основан на оценке степени близости гистограммы относительных частот выборки и известной плотности распределения . Для построения гистограммы проводят группировку выборочных значений на k интервалов J1,…,Jk, где J1 = [α0 = x(1); α1), J2 = [α1; α2),…, Jk = [αk-1; αk = x(n)]. Все интервалы выбираются, как правило, одинаковой ширины h.
Пусть ni – число элементов выборки, принадлежащих интервалу Ji, . Очевидно, что для частот выполняется равенство .
На основе известной функции плотности распределения g(x) рассчитываются вероятности попадания в каждый интервал:
, .
Полученные результаты представлены в виде таблицы.
Число наблюдений |
Всего |
|||
J1 |
... |
Jk |
||
Наблюдаемое |
n1 |
... |
nk |
n |
Ожидаемое |
np1 |
... |
npk |
n |
Относительная частота является состоятельной оценкой вероятности pi, . Это означает, что для каждого интервала Ji, , при условии истинности основной гипотезы вероятность того, что рассогласование между и pi примет достаточно большие значения, стремится к нулю при .
В качестве меры рассогласования между и pi используется статистика
$Z=n\sum\limits_{i=1}^{k}{\frac{(\tilde p_i-p_i)^2}{p_i}=\sum\limits_{i=1}^{k}{\frac{(n_i-np_i)^2}{np_i}$.
для которой показано, что при условии истинности основной гипотезы H0 при её закон распределения не зависит от вида функции G(x) и стремится к распределению «хи-квадрат» с k–r–1 степенями свободы, где r – число неизвестных параметров распределения FX(x, θ) (теорема Пирсона).
Использование статистики Z возможно также для проверки согласия выборочных данных с дискретным распределением генеральной совокупности. В этом случае в качестве вероятностей p1,…,pk следует брать вероятности дискретных значений генеральной совокупности ( ), а в качестве частот – относительные частоты этих значений в выборке. При необходимости близкие дискретные значения могут быть сгруппированы.
Если требуется проверить принадлежность функции распределения FX(x, θ) заданному параметрическому множеству распределений G(x, θ), θ∈Θ, то проверяется согласие лишь с максимально правдоподобным для данной выборки распределением , где – МП-оценка параметра θ.
Аппроксимация закона распределения статистики Z при условии истинности основной гипотезы H0 законом с высокой точностью возможна лишь при больших значениях ожидаемых абсолютных частот npi, . В случае если для некоторых интервалов npi < 5, то такие интервалы рекомендуется объединить с соседними.
Аналогично критериям Колмогорова и «омега-квадрат», в критерии Пирсона критическая область выбирается правосторонней.
Проверка гипотез об однородности выборок. Критерий знаков
В практических приложениях наряду с задачей о соответствии выборочных наблюдений предполагаемому закону распределения может возникнуть задача о проверке соответствия распределений двух генеральных совокупностей по результатам выборочных наблюдений.
Пусть – выборка объёма nX наблюдений случайной величины X, имеющей неизвестное распределение FX(x), – выборка объёма nY наблюдений случайной величины Y, имеющей неизвестное распределение FY(y). Выборки и называются однородными, если FX(ξ) = FY(ξ). Иными словами, выборки однородные, если они получены из одной и той же генеральной совокупности, или являются наблюдениями одной и той же случайной величины.
Сформулируем основную и альтернативную гипотезы однородности:
|
, . |
Одним из наиболее простых и грубых критериев проверки гипотезы об однородности распределения случайных величин Х и Y является критерий знаков. Критерий знаков (sign test) используется для проверки однородности двух связанных выборок (paired samples). Такие выборки получаются в результате наблюдений двумерного случайного вектора (X, Y). Объёмы связанных выборок всегда равны.
Критерий знаков является примером непараметрического критерия математической статистики, т.е. критерия, использующего не сами численные значения элементов выборки, а структурные свойства выборки (например, отношения порядка между её элементами, знаки и пр.). Мощность непараметрических критериев, как правило, меньше, чем мощность их параметрических аналогов. Причина этого связана с неизбежной потерей части информации, содержащейся в выборке. Однако непараметрические методы могут применяться при менее строгих предположениях о свойствах наблюдаемых случайных величин и, как правило, более просты с вычислительной точки зрения.
Если выборки получены из одной и той же генеральной совокупности, то значения xi и yi, , взаимозаменяемы, и, следовательно, вероятности появления положительных и отрицательных разностей xi и yi равны, т.е.
|
. |
Пусть K – число знаков «+» в последовательности знаков разностей x1 – y1,…,xn – yn. Если в этой последовательности разностей содержатся нулевые элементы, то они исключаются из рассмотрения. Далее для простоты будем считать, что в последовательности x1 – y1,…,xn –yn нулевых элементов нет. При условии, что основная гипотеза H0 верна, а пары наблюдений (Xi,Yi), , и, следовательно, знаки разностей Xi – Yi независимы, число K знаков «+» имеет биномиальное распределение B(n, 1/2). Таким образом, проверка гипотезы однородности (1) сводится к проверке гипотезы о параметре p биномиального распределения:
,
.
Несложно показать, что эта гипотеза эквивалентна гипотезе о равенстве медиан распределений FX(x) и FY(y).
Математическое ожидание и дисперсия . В соответствии с предельной теоремой Муавра-Лапласа при большом числе испытаний n статистика K имеет закон распределения, близкий к нормальному:
.
Частота «успеха» также имеет нормальное распределение .
В качестве статистики критерия используется стандартизованная частота:
которая при условии истинности H0 имеет распределение .
Основная гипотеза H0 должна отклоняться при больших отличиях частоты знаков «+» от значения 1/2 как в меньшую, так и в большую сторону, т.е. в области больших абсолютных значений статистики критерия Z. Таким образом, критическая область для статистики Z должна выбираться двусторонней.
Условие (2) является необходимым, но не достаточным условием однородности выборок и . Это означает, что из принятия основной гипотезы критерия знаков не следует однородность выборок, а следует лишь возможность однородности. Если же основная гипотеза критерия знаков отклоняется, то отклоняется и гипотеза однородности выборок.
Критерий Манна-Уитни
Критерий Манна-Уитни является ещё одним непараметрическим критерием проверки статистической гипотезы об однородности выборок:
,
.
Критерий был предложен Уилкоксоном (Frank Wilcoxon, 1945) и существенно переработан и расширен Манном и Уитни (Henry Mann, Donald Whitney, 1947). Критерий Манна-Уитни является одним из наиболее популярных непараметрических критериев проверки статистической гипотезы об однородности выборок. Другие названия критерия – критерий Манна-Уитни-Уилкоксона и критерий суммы рангов Уилкоксона (Mann-Whitney-Wilcoxon test, MWW-test, U-test).
Критерий Манна-Уитни использует тот факт, что если выборки и получены из одной и той же генеральной совокупности, то элементы как первой, так и второй выборок в вариационном ряду объединённой выборки , – суммарный объём выборок, перемешаны равномерно.
Для оценки степени перемешивания данных двух выборок проводится ранжирование объединённой выборки . Рангом элемента zi в выборке называется его порядковый номер в вариационном ряду . Минимальный элемент выборки имеет ранг 1, максимальный элемент – ранг N. Если несколько выборочных значений в вариационном ряду равны, то им приписываются одинаковые ранги, равные среднему арифметическому из их порядковых номеров.
В результате ранжирования для выборки получаем выборку соответствующих рангов . Обозначим через RX – сумму рангов в ряду , соответствующих элементам из первой выборки, RY – элементам из второй выборки.
Несложно показать, что
,
.
Минимальное значение суммы рангов RX элементов первой выборки достигается, когда все они преобладают на левом конце объединённого вариационного ряда, максимальное значение – когда на правом.
Введём статистики UX и UY, линейно связанные с суммами рангов RX и RY:
,
,
.
В качестве меры степени перемешивания элементов двух выборок в критерии Манна-Уитни используется любая из статистик UX или UY. При равномерном перемешивании элементов выборочные значения статистик UX и UY будут близки к их средним по диапазону изменения значениям .
При условии истинности основной гипотезы H0 при , закон распределения статистик UX и UY не зависит от вида функций FX(x) и FY(y), причём их распределение стремится к нормальному:
.
В качестве статистики критерия выберем любую из стандартизованных статистик UX и UY (например, UX):
,
которая при условии истинности H0 имеет распределение . На практике распределение статистики Z можно аппроксимировать нормальным уже при nX > 10, nY > 10, что делает критерий Манна-Уитни применимым для проверки гипотезы об однородности для малых выборок.
Основная гипотеза H0 должна отклоняться при больших отличиях статистики UX от среднего значения , т.е. в области больших по модулю значений статистики критерия Z. Таким образом, критическая область для статистики Z должна выбираться двусторонней.
Модифицированные критерии Колмогорова, "омега-квадрат", "хи-квадрат"
Пусть – выборка объёма nX наблюдений случайной величины X, имеющей неизвестное распределение FX(x), – выборка объёма nY наблюдений случайной величины Y, имеющей неизвестное распределение FY(y).
Параметрические критерии проверки статистической гипотезы об однородности
,
;
основаны на оценке рассогласования между эмпирическими функциями распределения и . Здесь могут быть использованы те же самые метрики, что и в критериях Колмогорова, «омега-квадрат» и Пирсона. Такие критерии, модифицированные для случая двух выборок, называются двухвыборочными (two-sample tests).
1. Двухвыборочный критерий Колмогорова (two-sample KS-test).
В критерии Колмогорова используется статистика критерия
,
где – расстояние по Колмогорову между эмпирическими функциям распределения и случайных величин X и Y соответственно:
.
Для статистики показано, что при условии истинности основной гипотезы H0 при , её закон распределения не зависит от вида функций FX(x) и FY(y), причём её распределение стремится к распределению Колмогорова. Аппроксимация распределения статистики распределением Колмогорова даёт хорошие результаты уже при nX > 40, nY > 40.
Так же, как и в критерии согласия Колмогорова, здесь основная гипотеза H0 должна отклоняться в области больших значений , т.е. критическая область должна выбираться правосторонней.
На практике для вычисления рассогласования между ЭФР и удобно использовать формулу:
,
где – вариационный ряд объединённой выборки , – суммарный объём выборок.
2. Двухвыборочный критерий «омега-квадрат» (two-sample omega-squared test).
Метрика «омега-квадрат» для расчёта рассогласования между функциями FX(x) и FY(y) на основе результатов наблюдений и имеет вид:
,
где – объединённая выборка , – суммарный объём выборок.
В двухвыборочном критерии «омега-квадрат» (критерии Крамера-Мизеса) используется статистика
,
для которой показано, что при условии истинности основной гипотезы H0 при , её закон распределения не зависит от вида функций FX(x) и FY(y), причём её распределение стремится к распределению «омега-квадрат».
Аналогично критерию согласия «омега-квадрат», основная гипотеза H0 должна отклоняться в области больших значений , т.е. критическая область должна выбираться правосторонней.
На практике для вычисления выборочного значения статистики Крамера-Мизеса удобно использовать формулу:
,
где
,
а ri и sj – ранги элемента xi в выборке и элемента yj в выборке соответственно, , .
3. Двухвыборочный критерий Пирсона (two-sample chi-squared test) .
Двухвыборочный критерий Пирсона, или критерий «хи-квадрат», основан на оценке степени близости гистограмм относительных частот выборок и . Для построения гистограмм проводят группировку выборочных значений обеих выборок на k интервалов J1,…, Jk, где J1 = [α0 = x(1); α1), J2 = [α1; α2),…,Jk = [αk-1; αk = x(n)], как правило, одинаковой ширины h (см. §2). Полученные результаты представлены в виде таблицы.
Число наблюдений |
Всего |
|||
J1 |
... |
Jk |
||
Наблюдаемых в выборке X |
... |
nX |
||
Наблюдаемых в выборке Y |
... |
nY |
||
В качестве меры рассогласования между относительными частотами и используется статистика:
для которой показано, что при условии истинности основной гипотезы H0 при , её закон распределения не зависит от вида функций FX(x) и FY(y), причём её распределение стремится к распределению «хи-квадрат» с k–1 степенью свободы.
Аналогично критерию согласия Пирсона, основная гипотеза H0 должна отклоняться в области больших значений , т.е. критическая область должна выбираться правосторонней.
Аппроксимация закона распределения статистики при условии истинности основной гипотезы H0 законом с высокой точностью возможна лишь при больших значениях частот и , . В случае если для некоторых интервалов или , то такие интервалы рекомендуется объединить с соседними.
Анализ статистических взаимосвязей
Виды связей между величинами
При изучении объектов и явлений исследователю, как правило, приходится иметь дело с несколькими некоторым образом связанными статистическими признаками. Например, объём продукции предприятия связан с численностью работников, мощностью оборудования, стоимостью производственных фондов и еще многими признаками. Признаки «пол» и «число лейкоцитов в крови» могли бы рассматриваться как зависимые, если бы большинство мужчин имело высокий уровень лейкоцитов, а большинство женщин – низкий, или наоборот. Рост связан с весом, потому что обычно высокие индивиды тяжелее низких; IQ (коэффициент интеллекта) связан с количеством ошибок в тесте, т.к. люди высоким значением IQ делают меньше ошибок и т.д.
Невозможно управлять явлениями, предсказывать их развитие без изучения характера, силы и других особенностей связей. Поэтому методы исследования, направленные на измерение связей, составляют чрезвычайно важную часть методологии научного исследования, в том числе и статистического.
При исследовании причинно-следственных связей статистические признаки разделяют на факторные и результативные. Факторные признаки, или факторы, – это признаки, обуславливающие изменение других, связанных с ними, признаков. Результативными называются признаки, изменяющиеся под воздействием факторных признаков.
Различают два типа связей между факторными и результативными признаками: функциональную и статистическую. Функциональной называют такую связь, при которой каждому определённому значению x факторного признака соответствует одно и только одно значение y результативного признака:
.
Функциональная связь двух величин возможна лишь при условии, что вторая из них зависит только от первой и ни от чего более. Такие связи являются абстракциями, в реальной жизни они встречаются редко, но находят широкое применение в точных науках и в первую очередь, в математике. Например, зависимость площади круга от радиуса .
Функциональная зависимость результативного признака y от многих факторов x1,…,xk возможна только в том случае, если признак y всегда зависит от перечисленного набора факторов и ни от чего более. Такие связи также являются абстракциями, поскольку большинство явлений и процессов безграничного реального мира связаны между собой, и нет такого конечного числа переменных, которые абсолютно полно определяли бы собою зависимую величину. Тем не менее, на практике нередко используют представление реальных связей как функциональных. Например, длина года (период обращения Земли вокруг Солнца) почти функционально зависит только от массы Солнца и расстояния Земли от него. На самом деле она зависит в очень слабой степени и от масс, и от расстояний других планет от Земли, но вносимые ими (и тем более в миллионы раз более далекими звездами) искажения функциональной связи для всех практических целей, кроме космонавтики, пренебрежимо малы.
Статистической связью между результативным и факторным признаками называется связь, при которой каждому определённому значению x факторного признака соответствует некоторое распределение вероятностей значений результативного признака.
Такие связи имеют место, например, если на результативный признак действуют несколько факторных признаков, а для описания связи используется один или несколько определяющих (учтённых) факторов.
Частным случаем статистической связи между результативным и факторным признаками y и x является корреляционная связь. При корреляционной связи от значения x факторного признака зависит не всё распределение вероятностей FY(y), а лишь математическое ожидание величины Y. Математическое ожидание случайной величины Y при фиксированном значении случайной величины X = x называется условным математическим ожиданием и обозначается M[Y|x], а уравнение
называется уравнением регрессии Y на X.
В зависимости от типа рассматриваемых статистических признаков для анализа статистических связей между ними используют различные статистические методы (табл. 6.1).
Для анализа степени тесноты связи между количественными факторным и результативным признаками, т.е. признаками, варианты которых имеют числовое выражение, используются методы корреляционного анализа, для анализа уравнения регрессии – методы регрессионного анализа. Корреляционный и регрессионный анализы также могут быть применены для случая качественных порядковых, или ординальных, признаков, т.е. признаков, значения которых могут быть некоторым образом упорядочены. Для таких признаков можно сказать, какие значения больше или меньше, но нельзя сказать насколько.
В случае если факторный признак является номинальным (категориальным, или атрибутивным), т.е. признаком, варианты которого могут быть измерены только в терминах принадлежности к некоторым категориям, а результативный – количественным, то для анализа статистической связи между ними используются методы дисперсионного анализа.
Если же оба признака – и факторный, и результативный – являются номинальными, то для анализа статистической связи между ними используют метод таблиц сопряжённости.
Если факторный признак является количественным, а результативный – номинальным, то задачу, как правило, сводят к случаю двух номинальных признаков путём группировки значений факторного признака.
Таблица 6.1
Методы исследования статистических связей
факторный результативный |
номинальный |
количественный |
номинальный |
таблицы сопряжённости |
таблицы сопряжённости |
количественный |
дисперсионный анализ |
корреляционный, |
Анализ статистической связи между номинальными величинами. Таблицы сопряженности
Пусть (X, Y) – вектор номинальных случайных величин X и Y, т.е. величин, значения которых нельзя выразить количественно (например, это может быть имя, город, национальность и т.п.). Номинальные случайные величины обязательно являются случайными величинами дискретного типа. Обозначим k – число вариантов случайной величины X, l – число вариантов случайной величины Y. Пусть распределение случайного вектора (X, Y) описывается таблицей:
Варианты |
y1 |
... |
yj |
... |
yl |
Σ |
x1 |
p11 |
... |
p1j |
... |
p1l |
|
... |
... |
... |
... |
... |
... |
... |
xi |
pi1 |
... |
pij |
... |
pil |
|
... |
... |
... |
... |
... |
... |
... |
xk |
pk1 |
... |
pkj |
... |
pkl |
|
Σ |
... |
... |
1 |
В последнем столбце и последней строке приведены маргинальные распределения случайных величин X и Y соответственно, вероятности , , .
Будем считать, что признак x является факторным, а признак y – результативным. При каждом фиксированном варианте xi случайной величины X, , случайная величина Y имеет распределение вероятностей, представленное в i‑ой строке таблицы. При отсутствии статистической связи между случайными величинами X и Y распределение вероятностей случайной величины Y не зависит от значений случайной величины X и совпадает с её маргинальным распределением, т.е. должно выполняться равенство:
Используя определение условной вероятности, запишем эквивалентное равенству (1) условие:
Пусть – выборка наблюдений случайного вектора (X, Y) объёма n. Обозначим через nij частоту пары в этой выборке, , . Таблица, составленная из этих частот, называется (эмпирической) таблицей сопряжённости (contingency table, crosstab) (табл. 6.2).
Таблица 6.2
Таблица сопряжённости
Варианты |
y1 |
... |
yj |
... |
yl |
Σ |
x1 |
n11 |
... |
n1j |
... |
n1l |
|
... |
... |
... |
... |
... |
... |
... |
xi |
ni1 |
... |
nij |
... |
nil |
|
... |
... |
... |
... |
... |
... |
... |
xk |
nk1 |
... |
nkj |
... |
nkl |
|
Σ |
... |
... |
n |
Сформулируем статистическую гипотезу об отсутствии статистической связи между случайными величинами X и Y:
|
, . |
В случае если основная гипотеза H0 верна, т.е. справедливы равенства (2), в таблице сопряжённости вместо наблюдаемых частот nij, , , будут стоять теоретические частоты :
,
из которых можно составить теоретическую таблицу сопряжённости.
Для проверки статистической гипотезы (3) используется критерий, основанный на оценке степени близости между частотами в эмпирической и теоретической таблицах сопряжённости. В качестве меры рассогласования используется статистика
для которой показано, что при условии истинности основной гипотезы H0 при её закон распределения стремится к распределению «хи-квадрат» с (k–1)*(l–1) степенями свободы. На практике закон распределения статистики критерия Z может быть аппроксимирован с высокой точностью законом , если выполняется условие mij > 5 для всех , .
В связи с тем, что основная гипотеза H0 должна отвергаться при больших рассогласованиях между частотами в эмпирической и теоретической таблицах сопряжённости, то критическая область для статистики критерия Z должна выбираться правосторонней.
Статистика критерия (4) может быть применена для анализа значимости статистической связи между двумя количественными признаками. В этом случае признаки должны быть предварительно группированы, а результаты группировки представлены в виде корреляционной таблицы.
Виды дисперсий в совокупности, разделённой на части
Пусть исследуемая генеральная совокупность разделена по некоторому номинальному признаку на группы. Например, при исследовании доходов предприятий в различных регионах страны множество предприятий разделено на группы по признаку «территориальное расположение», при исследовании качества продукции различных производителей генеральная совокупность разделена на группы по признаку «производитель» и т.п. Пусть в каждой группе проведено выборочное наблюдение, в результате которого получена выборка значений интересующего количественного признака.
Ставится задача определить, есть ли значимая статистическая связь между группировочным признаком (фактором) и интересующим результативным признаком.
Введём следующие обозначения: G – номинальный группировочный признак, имеющий K вариантов, X – количественный результативный признак, – выборка наблюдений случайной величины X объёма nk, соответствующая k-му варианту групппировочного признака, . Для выборки из каждой группы могут быть рассчитаны выборочные характеристики:
– частное (групповое) среднее, ;
– частная (групповая) дисперсия, .
Выборочные характеристики объединённой выборки :
– общее среднее;
– общая дисперсия;
где – общий объём выборки.
Несложно показать, что общее среднее представляет собой среднее арифметическое групповых средних, взвешенное объёмами выборок:
.
Аналогично, введём среднее арифметическое групповых дисперсий, взвешенное объёмами выборок:
Величина, рассчитываемая по этой формуле, называется внутригрупповой дисперсией (within-group variance) выборок , .
Общая дисперсия является мерой разброса (вариации) выборочных данных объединённой выборки, внутригрупповая дисперсия – мерой разброса данных внутри каждой группы. Мерой разброса групповых средних является межгрупповая дисперсия (between-group variance), определяемая выражением:
.
Можно показать, что для внутригрупповой, межгрупповой и общей дисперсий справедливо правило сложения дисперсий:
.
Правило сложения дисперсий имеет следующую интерпретацию: общая вариация результативного признака X складывается из его вариации внутри каждой группы (при каждом фиксированном значении группировочного признака G) и вариации групповых средних. Вариация значений признака X внутри каждой группы не может быть обусловлена признаком G (поскольку внутри каждой группы он имеет фиксированное значение) и связана с действием других факторов, называемых остаточными. В то же время, вариация групповых средних связана именно с действием фактора G. Таким образом, может быть предложна ещё одна интерпретация правила сложения дисперсий: вариация результативного признака X складывается из вариации, обусловленной действием остаточных факторов, и вариации, связанной с группировочным признаком G.
Отношение межгрупповой дисперсии к общей дисперсии называется эмпирическим коэффициентом детерминации (ЭКД):
|
. |
Возможные значения ЭКД . ЭКД показывает, какая доля в общей вариации результативного признака X связана с действием группировочного признака G. ЭКД нередко называют также показателем «эта-квадрат» (eta-squared).
Отношение межгруппового среднеквадратического отклонения к общему среднеквадратическому отклонению называется эмпирическим корреляционным отношением (ЭКО):
.
Возможные значения ЭКО . На основе ЭКО судят о степени тесноты статистической связи между факторным признаком G и результативным признаком X. Для характеристики степени тесноты связи может быть использована шкала Чеддока (R. E. Chaddock, 1925) (табл. 6.3).
Таблица 6.3
Шкала Чеддока
η |
Степень тесноты связи |
0,1–0,3 |
слабая |
0,3–0,5 |
умеренная |
0,5–0,7 |
заметная |
0,7–0,9 |
высокая |
0,9–0,99 |
сильная |
0,99–1 |
функциональная |
При расчётах внутригрупповой, межгрупповой и общей дисперсий, а также ЭКД и ЭКО по результатам выборочного наблюдения необходимо иметь в виду, что все получаемые значения являются смещёнными оценками соответствующих теоретических значений, характеризующих генеральную совокупность. Показатели вариации, а также их несмещённые оценки сведены в таблицу, называемую таблицей дисперсионного анализа (табл. 6.4).
Таблица 6.4
Таблица дисперсионного анализа
Источник вариации |
Показатель вариации |
Число степеней свободы |
Несмещённая оценка |
Группировочный признак |
K–1 |
||
Остаточные признаки |
n–K |
||
Все признаки |
n–1 |
Смещение оценки ЭКД, рассчитываемой по формуле (1), является положительным, т.е. такая оценка в среднем даёт завышенную долю объяснённой дисперсии. Однако с ростом объёма выборки величина смещения уменьшается. При малом объёме выборки вместо оценки ЭКД (1) рекомендуется использовать другую оценку, обладающую меньшим смещением:
Оценка ЭКД, рассчитываемая по формуле (2), всегда меньше оценки, рассчитываемой по формуле (1).
Однофакторный дисперсионный анализ
При исследовании влияния номинального группировочного признака G на количественный результативный признак X задача проверки значимости статистической связи между этими признаками может быть сведена к задаче проверки статистической гипотезы о равенстве математических ожиданий случайных величин X1,…, XK, соответствующих каждому варианту группировочного признака G. Для проверки такой гипотезы используется дисперсионный анализ (Analysis of Variance, ANOVA).
Поскольку рассматривается единственный группировочный признак G (фактор), то дисперсионный анализ называется однофакторным (one-way ANOVA).
Пусть – выборка объёма nk из k-ой группы, т.е. результаты наблюдений случайной величины Xk, . В дисперсионном анализе выдвигаются следующие предположения:
1) все случайные величины X1,…, XK имеют нормальное распределение;
2) выборки из каждой группы являются независимыми;
3) дисперсии случайных величин X1,…,XK равны (такие случайные величины называются гомоскедастичными).
Учитывая эти предположения, гипотеза об отсутствии статистической связи между группировочным и результативным признаками
эквивалентна гипотезе о математических ожиданиях
,
.
Для проверки этой гипотезы используется статистика:
.
которая при условии истинности основной гипотезы H0 имеет распределение Фишера F(K–1, n–K). Фактически, статистика F представляет собой отношение несмещённых оценок межгрупповой и внутригрупповой дисперсий. При наличии статистической связи между группировочным и исследуемым признаками (случай отклонения гипотезы H0) межгрупповая дисперсия много больше внутригрупповой дисперсии, из чего следует, что критическая область должна выбираться правосторонней.
Дисперсионный анализ является слабо чувствительным (робастным) к требованию о нормальности распределения наблюдаемых случайных величин при больших и сбалансированных объёмах выборок, а при нарушении требования их гомоскедастичности наблюдается рост вероятности ошибки второго рода.
В частном случае число вариантов K группировочного признака может быть равно 2. Тогда гипотеза дисперсионного анализа имеет вид:
,
.
Эта гипотеза является двухвыборочной параметрической гипотезой и для её проверки может быть использована статистика критерия Стьюдента.
Основная гипотеза H0 дисперсионного анализа состоит в том, что математические ожидания в каждой из K групп равны против альтернативной гипотезы, состоящей в том, что математические ожидания хотя бы в двух группах окажутся различными. Такая альтернатива включает множество вариантов. Основная гипотеза дисперсионного анализа будет отклонена как в случае значимого различия математических ожиданий лишь в двух группах, так и в случае значимого различия математических ожиданий всех групп.
В случае, когда основная гипотеза H0 в результате дисперсионного анализа отклоняется, нередко бывает необходимо узнать, какие именно математические ожидания значимо отличаются, а какие равны. Возможным способом такой проверки является проведение попарных сравнений математических ожиданий для каждой пары групп, т.е. проверка множества статистических гипотез вида:
,
.
где , .
Однако такой способ проверки имеет существенный недостаток. При проверке одной параметрической гипотезы задаётся некоторый уровень значимости α, определяющий вероятность ошибки первого рода, т.е. отклонения основной гипотезы при условии её истинности. При проверке множества параметрических гипотез, каждую на уровне значимости α, с использованием статистики критерия Стьюдента, вероятность ошибочно обнаружить различие в математических ожиданиях будет расти с числом проверяемых гипотез.
Вероятность ошибки первого рода при проверке K независимых статистических гипотез будет равна
.
В случае зависимых гипотез может быть рассчитана оценка эффективной вероятности ошибки первого рода, используя различные корректирующие поправки (например, поправку Бонферрони).
Для того, чтобы обеспечить заданную вероятность ошибки первого рода при проверке множества параметрических гипотез вида , ,, на практике используются методы множественного сравнения (multiple comparison tests).
Одним из методов множественного сравнения является метод Шеффе (Henry Scheffe, 1953), называемый также методом линейных контрастов. С помощью метода Шеффе проверяется основная гипотеза вида:
,
,
где c1,…,cK – весовые коэффициенты, причём . Величина называется линейным контрастом. В частном случае, при , , , и остальных нулевых коэффициентах, линейный контраст , а проверяемая гипотеза имеет вид:
,
.
Для проверки гипотезы H0 используем метод доверительных интервалов. Точечной оценкой линейного контраста является линейная комбинация групповых средних
,
которая для конкретной выборки примет выборочное значение
.
Можно показать, что оценка дисперсии линейного контраста равна
,
а границы доверительного интервала имеют вид:
,
где – квантиль распределения Фишера с K–1 и n–K степенями свободы на уровне значимости 1–α.
В случае, если доверительный интервал накрывает нулевое значение, то нет оснований отвергать основную гипотезу о равенстве нулю линейного контраста.
Статистическая связь между компонентами нормально распределенного случайного вектора
Частным случаем статистической связи между количественными признаками x и y является корреляционная связь. При корреляционной связи от значения x факторного признака зависит лишь условное математическое ожидание M[Y | x] случайной величины Y, при этом все остальные характеристики распределения случайной величины Y остаются неизменными. Функция f(x), описывающая эту зависимость, называется функцией регрессии Y на X.
Частным случаем корреляционной связи между признаками x и y является линейная корреляционная связь, когда функция регрессии Y на X представляет собой линейную функцию:
.
Пусть случайный вектор имеет двумерное нормальное распределение, , где – вектор математических ожиданий, – ковариационная матрица. Покажем, что если между случайными величинами X и Y есть статистическая связь, то такая связь является линейной корреляционной связью.
Запишем двумерную функцию плотности распределения случайного вектора Z в матричном виде:
,
где . В скалярном виде:
|
, |
где – коэффициент корреляции.
Путём интегрирования по соответствующей переменной двумерной функции плотности (1) получим маргинальные распределения случайных величин X и Y:
Из равенств (1), (2) и (3) видно, что в случае если , выполняется тождество:
,
из которого следует, что если нормально распределённые случайные величины X и Y некоррелированы, то они независимы. Для произвольного закона распределения это утверждение в общем случае неверно.
По определению, условная плотность распределения случайной величины Y:
.
Подставляя выражения (1 )и (2), получим
где использованы обозначения
|
, |
|
. |
Из (4)–(6) следует, что при любом фиксированном значении x распределение случайной величины Y является нормальным распределением с постоянной дисперсией . Это означает, что статистическая связь между величинами X и Y может быть только корреляционной. Покажем, что эта связь линейна.
Используя определения условного математического ожидания и среднеквадратичного отклонения, получим, что для случайной величины Y они равны соответственно и :
|
, |
Учитывая линейную зависимость (5), заключаем, что функция регрессии Y на X является линейной. Это означает, что статистическая связь между нормально распределёнными случайными величинами может быть только линейной корреляционной. Из (5) получаем коэффициенты линейной регрессии:
|
, . |
Из этих равенств видно, что функция регрессии не зависит от x ( ), если коэффициент корреляции . Таким образом, некоррелированность нормально распределённых случайных величин означает отсутствие статистической связи между ними. Можно показать, что если , то между случайными величинами X и Y имеется линейная функциональная связь:
.
Следовательно, коэффициент корреляции можно рассматривать как показатель тесноты статистической связи между нормально распределёнными случайными величинами X и Y.
На рисунке ниже показаны диаграммы рассеяния (в корреляционном анализе называемые корреляционными полями) двумерных нормальных распределений при различных значениях коэффициента корреляции.
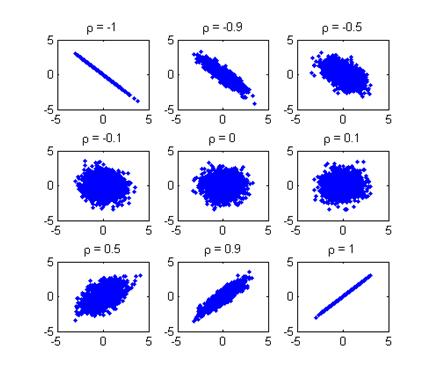
С изменением коэффициента корреляции от –1 до 1 прямая регрессии изменяет угол наклона, от минимального значения до максимального , кроме того, изменяется степень рассеяния выборочных значений относительно прямой регрессии – при рассеяние максимально, а при рассеяние отсутствует.
Согласно (9), угол наклона линии регрессии зависит не только от коэффициента корреляции , но и от отношения с.к.о. . На рисунке ниже показаны корреляционные поля двумерных нормальных распределений при фиксированном значении коэффициента корреляции и различных значениях отношения .
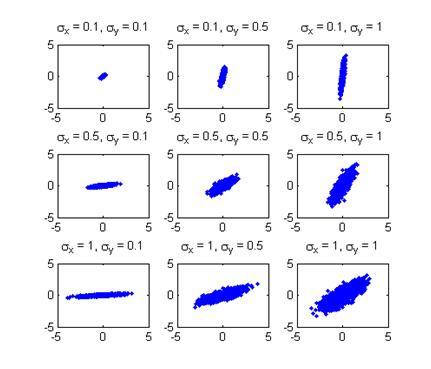
Из диаграмм рассеяния видно, что угол наклона прямой регрессии может изменяться практически от 0 до π/2 в зависимости от соотношения с.к.о. при фиксированном значении коэффициента корреляции ρXY, кроме того, изменяется степень рассеяния выборочных значений относительно прямой регрессии, определяемая условными с.к.о. и .
Корреляционное отношение
Если закон распределения случайного вектора не является нормальным, то характер изменения условного математического ожидания в общем случае является нелинейным, а условная дисперсия зависит от x. При каждом фиксированном x условная дисперсия является мерой рассеяния условного распределения относительно условного математического ожидания , т.е. относительно значения функции регрессии в точке x.
Рассеяние случайной величины Y относительно её математического ожидания mY складывается из двух слагаемых, а именно: рассеяния случайной величины Y относительно функции регрессии и рассеяния значений функции регрессии относительно математического ожидания случайной величины Y, т.е.
Для доказательства преобразуем левую часть равенства:
.
Учитывая, что
|
, |
получаем верное равенство (1).
Величина характеризует степень разброса значений случайной величины Y относительно линии регрессии и называется остаточной дисперсией случайной величины Y (residual variance).
Величина характеризует степень разброса значений, принадлежащих линии регрессии, относительно математического ожидания случайной величины Y и называется дисперсией, обусловленной регрессией Y на X (variance explained by regression).
Таким образом, для общей дисперсии Y, дисперсии, обусловленной регрессией Y на X, и остаточной дисперсии Y справедливо правило сложения дисперсий:
.
Отношение дисперсии, обусловленной регрессией Y на X, к общей дисперсии случайной величины Y называется коэффициентом детерминации (КД) Y на X:
|
. |
Возможные значения КД . КД показывает, какая доля в общей вариации результативного признака Y связана с вариацией линии регрессии. Иными словами, КД – это доля вариации, объяснённой регрессией, в общей вариации значений признака Y.
Отношение среднеквадратичного отклонения, обусловленного регрессией Y на X, к среднеквадратичному отклонению случайной величины Y называется корреляционным отношением (КО) Y на X:
.
Возможные значения КО . На основе КО судят о степени тесноты корреляционной связи между факторным признаком X и результативным признаком Y. Для характеристики степени тесноты связи может быть использована шкала Чеддока (табл. 6.3).
Равенство означает, что вариация значений функции регрессии f(x) при различных значениях x полностью отсутствует, линия регрессии является горизонтальной прямой ( ). Другими словами, корреляционная связь между случайными величинами X и Y отсутствует.
Равенство будет иметь место, если остаточная дисперсия , т.е. если вариация признака Y относительно линии регрессии при каждом фиксированном значении x полностью отсутствует. Это означает, что при каждом значении x значение признака Y однозначно определено и равно f(x). Иными словами, между случайными величинами X и Y имеется функциональная связь.
Аналогично выражению (3) определяется КД X на Y.
Между и в общем случае нет какой-либо простой зависимости. Возможны ситуации, когда один из этих показателей принимает нулевое значение, в то время как другой равен единице. Так, на рисунке ниже приведён пример ситуации, когда , в то время как . В первом случае (слева) линия регрессии Y на X является параболой (сплошная линия), разброс данных относительно неё небольшой, т.е. , в то время как разброс значений, принадлежащих линии регрессии, относительно среднего значения случайной величины Y (горизонтальная пунктирная линия) много больше, т.е. . Во втором случае (справа) линия регрессии X на Y – прямая, параллельная оси Y. Линия регрессия проходит на уровне среднего значения случайной величины X, т.е. , в то время как разброс значений случайной величины X относительно линии регрессии практически равен разбросу относительно среднего значения случайной величины X, т.е. .
Иллюстрация к расчёту КД и
Рассмотрим, как связаны между собой коэффициент корреляции ρXY и корреляционное отношение . Из теории вероятностей известно, что из независимости случайных величин следует их некоррелированность. В терминах статистической связи это утверждение формулируется так: если между признаками отсутствует статистическая связь, то между ними отсутствует линейная корреляционная связь. Справедливость этого утверждения очевидна, поскольку линейная корреляционная связь – частный случай статистической связи. Обратное утверждение в общем случае неверно: отсутствие линейной корреляционной связи не означает отсутствие статистической связи какого-либо другого типа.
Ранее показано, что между компонентами двумерного нормально распределённого случайного вектора статистическая связь может быть лишь линейной корреляционной связью. Из этого следует, что термины «статистическая связь» и «линейная корреляционная связь» для нормального распределения эквивалентны. В теории вероятностей это утверждение известно как «из некоррелированности нормально распределённых случайных величин следует их независимость».
Рассчитаем КД для нормально распределённых случайных величин X и Y. По определению, коэффициент детерминации равен:
.
где – функция регрессии.
Учитывая, что условная дисперсия не зависит от x:
,
запишем
.
Таким образом, для нормально распределённых случайных величин коэффициент корреляции и корреляционное отношение совпадают с точностью до знака. Это означает, что использование корреляционного отношения в качестве показателя статистической связи имеет смысл лишь для признаков, распределения которых отличны от нормального. В случае же нормального распределения можно ограничиться рассмотрением лишь коэффициента корреляции.
При любом законе распределения случайного вектора для КД и коэффициента корреляции справедливо неравенство:
.
При этом возможны следующие варианты:
а) тогда и только тогда, когда линейная корреляционная связь между X и Y отсутствует;
б) тогда и только тогда, когда имеется линейная функциональная связь между X и Y;
в) тогда и только тогда, когда имеется нелинейная функциональная связь между X и Y;
г) тогда и только тогда, когда регрессия Y на X линейна, но функциональная связь отсутствует.
Оценивание коэффициента корреляции по выборочным данным
Пусть (x1, y1),…,(xn, yn) – выборка наблюдений двумерного случайного вектора (X, Y), имеющего неизвестное распределение FXY(x, y).
1. Точечная оценка коэффициента корреляции
На практике в качестве точечной оценки коэффициента корреляции ρXY используется выборочный коэффициент корреляции:
где – выборочный ковариационный момент:
.
Выборочный коэффициент корреляции является состоятельной смещённой оценкой коэффициента корреляции ρXY со смещением, равным . Величина смещения убывает с увеличением объёма выборки и при n > 30 уже становится практически пренебрежимой.
2. Интервальная оценка коэффициента корреляции
Пусть распределение FXY(x, y) является двумерным нормальным распределением. В этом случае точечная оценка коэффициента корреляции имеет асимптотически нормальный закон распределения с математическим ожиданием
и дисперсией
.
В качестве центральной статистики при построении доверительного интервала выберем стандартизованную оценку коэффициента корреляции:
.
Запишем тождество для статистики U:
,
где и – квантили стандартизованного нормального распределения на уровнях α/2 и 1–α/2 соответственно. Преобразуя неравенство под знаком вероятности, получим:
.
Это выражение ещё не даёт интервальной оценки коэффициента корреляции ρXY, так как левая и правая части неравенства под знаком вероятности содержат этот параметр. На практике в указанные части неравенств подставляют вместо неизвестного точного значения ρXY его оценку . В результате получается следующий интервал для ρXY:
,
являющийся доверительным для ρXY на уровне значимости α.
Подчеркнём, что указанные границы доверительного интервала являются приближёнными и могут использоваться лишь при достаточно больших объёмах выборки (n > 500).
При малых объёмах выборки границы доверительного интервала для ρXY могут быть рассчитаны по следующим приближённым формулам:
|
|
,
где – функция гиперболического тангенса.
Приведённые формулы расчёта границ доверительного интервала для коэффициента корреляции выведены в условиях нормальности распределения генеральной совокупности. Однако в случае отклонения от нормальности уже при объёмах выборки n > 30 возникающая неточность расчёта практически пренебрежима.
3. Проверка значимости коэффициента корреляции
Для проверки статистической гипотезы
в качестве статистики критерия используется статистика
которая при условии истинности H0 имеет распределение Стьюдента с n–2 степенями свободы .
Если альтернативная гипотеза , то критическая область для статистики критерия выбирается двусторонней, если или , то левосторонней или правосторонней соответственно.
Оценивание коэффициента детерминации и корреляционного отношения по выборочным данным
Пусть (x1, y1),…, (xn, yn) – выборка наблюдений двумерного случайного вектора (X, Y), имеющего неизвестное распределение FXY(x, y).
1. Точечные оценки КД и КО
В качестве точечной оценки коэффициента детерминации используют статистику
Такую оценку КД называют также показателем «эр-квадрат» (R-squared).
В качестве точечной оценки корреляционного отношения используют статистику
.
Для расчёта выборочной остаточной дисперсии необходимо знать функцию регрессии Y на X. Пусть эта функция имеет вид , где – известные параметры. Тогда, учитывая определение остаточной дисперсии, запишем выражение для выборочной остаточной дисперсии:
Если же для функции регрессии задан только её вид, а параметры оцениваются на основе результатов наблюдений (x1,y1),…,(xn,yn), то выборочная остаточная дисперсия рассчитывается по формуле
,
где – оценки параметров .
Выборочная дисперсия признака Y рассчитывается по известной формуле:
.
При обработке реальных данных встречаются случаи, когда ни вид, ни параметры функции регрессии бывают априорно не известны. В этом случае функция регрессии может быть оценена непосредственно по выборочным наблюдениям. Для этого проводится группировка выборочных значений x1,…,xn. Обозначим J1,…,Jk – интервалы группировки, ni – число выборочных точек, попадающих в интервал Ji, , k – число интервалов.
Пусть – выборочные наблюдения, попавшие в интервал Ji, . Для этих наблюдений рассчитываются групповые средние , где
Линия, соединяющая все групповые средние , и будет являться оценкой линии регрессии.
На практике для упрощения вычислений при расчёте оценки дисперсии, обусловленной регрессией Y на X, предполагается, что функция регрессии является кусочно-постоянной:
.
Число интервалов группировки k не должно быть слишком мало – в этом случае кусочно-постоянная аппроксимация функции регрессии будет неточной. С другой стороны, при слишком большом числе интервалов группировки становятся неточными оценки групповых средних.
Учитывая определение дисперсии, обусловленной регрессией, запишем выражение для выборочной дисперсии, обусловленной регрессией Y на X:
Можно показать, что для выборочных оценок общей дисперсии Y, дисперсии, обусловленной регрессией Y на X, и остаточной дисперсии Y справедливо правило сложения дисперсий:
.
Оценивание линии регрессии по выборочным данным. Жирными точками отмечены групповые средние
При расчётах дисперсии, обусловленной регрессией, остаточной дисперсии и общей дисперсии, а также КД и КО по результатам выборочного наблюдения необходимо иметь в виду, что все получаемые значения являются смещёнными оценками соответствующих теоретических значений, характеризующих генеральную совокупность. Показатели вариации, а также их несмещённые оценки сведены в таблицу, называемую таблицей регрессионного анализа (табл. 6.5).
Таблица 6.5
Таблица регрессионного анализа
Источник вариации |
Показатель вариации |
Число степеней свободы |
Несмещённая оценка |
Регрессия |
k–1 |
||
Остаточные признаки |
n–k |
||
Все признаки |
n–1 |
Здесь k – число оцениваемых параметров функции регрессии. Если при расчётах используется кусочно-постоянная аппроксимация функции регрессии, то это число равно числу интервалов группировки.
Смещение точечной оценки КД, рассчитываемой по формуле (1), равно
.
Это смещение всегда положительно, т.е. оценка КД (1) в среднем даёт завышенную долю дисперсии, объясненной регрессией. При больших k и малых n это смещение может достигать существенных значений и приводить к серьёзным ошибкам в интерпретации получаемых результатов. В частности, при смещение оценки КД равно
.
Пренебрегая единицей в числителе, это смещение имеет смысл величины, обратной числу наблюдений, приходящихся на один оцениваемый параметр уравнения регрессии. Например, для выборки объёма n = 18 из генеральной совокупности с КД, равным нулю, при числе оцениваемых параметров уравнения регрессии k = 6 (таким образом, три наблюдения на параметр), оценка КД в среднем будет равна 5/18 = 0,278. При смещение выборочного значения КД становится менее 0,01.
Оценкой КД, имеющей меньшее смещение, является отношение несмещённых оценок остаточной дисперсии и общей дисперсии признака Y за вычетом из единицы:
где
,
.
Учитывая выражение для расчёта показателя , запишем:
Эта оценка по-прежнему является смещённой, поскольку отношение двух несмещённых оценок в общем случае не является несмещённой оценкой отношения. Такая оценка называется скорректированной оценкой коэффициента детерминации. Скорректированную оценку КД называют также показателем «эр-бар-квадрат» (adjusted R-squared).
Показатели «эр-квадрат» и «эр-бар-квадрат» имеют принципиально различную интерпретацию. Показатель является мерой вариации признака Y, объяснённой регрессией f(x). Если вариация выборочных данных относительно линии регрессии отсутствует, т.е. все выборочные наблюдения лежат на линии регрессии, то . Если вариация самой линии регрессии отсутствует, т.е. , то .
Показатель всегда меньше показателя и может даже принимать отрицательные значения. Этот показатель можно рассматривать как сравнительную меру «объяснительных» способностей различных уравнений регрессии.
При большом отношении объёма выборки к числу параметров уравнения регрессии разница между и становится практически пренебрежимой.
2. Интервальные оценки КД и КО
При расчёте границ доверительных интервалов для КД и КО используются различные аппроксимации. Если распределение FXY(x, y) является двумерным нормальным распределением, то доверительный интервал на уровне значимости a для КД может быть аппроксимирован следующим интервалом:
,
где – квантиль распределения Стьюдента с n–k–1 степенями свободы на уровне 1–α/2, а – оценка с.к.о. показателя «эр-квадрат», рассчитываемая из формулы:
,
которая при может быть аппроксимирована выражением:
,
Для расчёта доверительного интервала для КО используется аппроксимация:
,
где и – квантили распределения Фишера с r1 и r2 степенями свободы в числителе и в знаменателе на уровнях α/2 и 1–α/2 соответственно. Степени свободы вычисляются по формулам:
где – целая часть числа.
На практике указанные аппроксимации применяются и для случая, когда распределение FXY(x, y) отличается от нормального, причём, чем больше отношение , тем выше точность аппроксимации.
3. Проверка значимости КД и КО
Для проверки статистической гипотезы
(или )
в качестве статистики критерия используют статистику
которая при условии истинности H0 имеет распределение Фишера с k–1 и n–k степенями свободы в числителе и в знаменателе соответственно: .
Критическая область для статистики критерия выбирается правосторонней.
Ранговый коэффициент корреляции по Спирмену
Пусть x1,…,xn – выборка наблюдений случайной величины X, имеющей распределение , – её вариационный ряд.
Рангом ri элемента xi выборки x1,…,xn называется его порядковый номер в вариационном ряду выборки, т.е.
, .
Ранг ri элемента xi можно рассматривать как реализацию случайной величины , определяемой как ранг случайной величины Xi в случайной выборке X1,…,Xn.
Ранговой статистикой Z называется произвольная функция от рангов R1,…, Rn:
.
В связи с тем, что статистика Z является функцией случайных аргументов, Z является случайной величиной. Для каждой реализации x1,…,xn случайной выборки X1,…,Xn получим соответствующие ей реализацию рангов r1,…,rn и реализацию z ранговой статистики Z:
.
Примечание. В случае если выборка x1,…,xn содержит одинаковые элементы, то им, как правило, приписывают одинаковый ранг, равный среднему из порядковых номеров этих элементов в вариационном ряду.
Пусть (x1, y1),…,(xn, yn) – выборка наблюдений двумерного случайного вектора (X, Y), имеющего распределение FXY(x, y); r1,…,rn – ранги элементов выборки x1,…,xn; s1,…,sn – ранги элементов выборки y1,…,yn.
Ранговым коэффициентом корреляции по Спирмену (Charles Spearman, 1904) называется ранговая статистика, определяемая следующим выражением:
где и – средние значения рангов:
|
. |
Выборочное значение этой статистики для выборки (x1, y1),…,(xn, yn) равно:
Фактически, значение рангового коэффициента корреляции по Спирмену для выборки (x1, y1),…,(xn, yn) – это значение линейного коэффициента корреляции для соответствующей выборки рангов (r1, s1),…,(rn, sn).
Учитывая (2), выражение (3) можно упростить:
Известно, что линейный коэффициент корреляции ρXY используется для обнаружения линейной корреляционной связи между величинами X и Y. Так, если , то между X и Y имеется линейная функциональная связь. Если ρXY = 0, то между X и Y отсутствует линейная корреляционная связь.
Значение будет означать, что между рангами R и S имеется линейная функциональная связь. Если же , то между рангами R и S отсутствует линейная корреляционная связь.
Рассмотрим, что означают эти случаи в пространстве признаков X и Y. Если X и Y связаны линейной функциональной зависимостью , то между рангами R и S также будет линейная зависимость. В самом деле, при бόльшим значениям X будут соответствовать бόльшие значения Y, таким образом, для отсортированной в порядке возрастания по X выборки (x1, y1),…,(xn, yn) соответствующая выборка рангов будет иметь вид:
ri |
1 |
... |
i |
... |
n |
si |
1 |
... |
i |
... |
n |
При :
ri |
1 |
... |
i |
... |
n |
si |
n |
... |
n-i+1 |
... |
1 |
Рассчитывая ранговый коэффициент по формуле (4), получим, что при : , при : .
Если , где φ(X) – монотонно возрастающая функция, то для отсортированной по X выборки (x1, y1),…,(xn, yn) соответствующая выборка рангов будет такой же, что и для случая линейной функциональной зависимости между X и Y при . Если φ(X) – монотонно убывающая функция, то выборка рангов будет такой же, что и для случая линейной функциональной зависимости между X и Y при .

Из рисунка видно, что переход к рангам «выпрямляет» монотонную зависимость исходных признаков.
Рассмотрим другой случай, когда признаки X и Y независимы. В этой ситуации случайный вектор рангов , составленный для случайной выборки , соответствующей отсортированным по возрастанию значениям выборки , с равной вероятностью является любой из возможных n! перестановок, составленных из чисел 1,…,n. Следовательно, математическое ожидание рангового коэффициента корреляции по Спирмену (1) будет равно нулю, т.е. . Можно показать, что дисперсия . Это означает, что значения выборочного рангового коэффициента корреляции по Спирмену при условии независимости случайных величин X и Y и большом объёме выборки будут группироваться вблизи нуля.

Из рисунка видно, что для независимых случайных величин X и Y выборочные ранги рассеяны практически равномерно внутри квадрата .
Для проверки значимости рангового коэффициента корреляции по Спирмену сформулируем основную гипотезу:
.
В качестве статистики критерия используют статистику:
,
которая при условии истинности H0 имеет распределение Стьюдента с n–2 степенями свободы: .
Критическая область для статистики критерия выбирается, исходя из вида альтернативной гипотезы.
Ранговый коэффициент корреляции по Кендаллу
Пусть (x1, y1),…,(xn, yn) – выборка наблюдений двумерного случайного вектора (X, Y), имеющего распределение FXY(x, y).
Ранговым коэффициентом корреляции по Кендаллу (Maurice Kendall, 1938) называется ранговая статистика, определяемая следующим выражением:
|
, |
где N+ – число пар наблюдений (xi, yi), (xj, yj), , для которых выполнено условие , N– – число пар наблюдений (xi, yi), (xj, yj), , для которых выполнено условие . Иными словами, N+ – это число наблюдаемых пар, у которых имеется одинаковая тенденция к изменению по обоим признакам: либо при увеличении значения одного увеличивается значение другого, либо при уменьшении значения одного уменьшается значение другого. N– – это число наблюдаемых пар с противоположными тенденциями к изменению. Ранговый коэффициент корреляции по Кендаллу также называют «тау Кендалла» (Kendall’s tau coefficient).
Отсортируем результаты наблюдений в порядке возрастания значений признака X. Тогда выборкой рангов признака X будет последовательность натуральных чисел 1,2,…,n (если все наблюдения x1,…,xn различны). Соответствующую выборку рангов признака Y обозначим s1,…,sn.
На практике для расчёта выборочного значения рангового коэффициента корреляции по Кендаллу используют формулу:
|
, |
где ,
|
– |
количество рангов в выборке , больших, чем si.
Примечание. Использование формулы (2) даёт верный результат лишь для случая, когда в выборках x1,…,xn и y1,…,yn отсутствуют повторяющиеся элементы. Однако при небольшом их количестве этой погрешностью на практике можно пренебречь.
Свойства и интерпретация рангового коэффициента корреляции по Кендаллу аналогичны свойствам и интерпретации рангового коэффициента корреляции по Спирмену. Так, при функциональной монотонно возрастающей зависимости между случайными величинами X и Y , при монотонно убывающей: . Для независимых случайных величин X и Y математическое ожидание .
Выборочные значения коэффициента корреляции по Спирмену, как правило, получаются выше (по абсолютной величине) выборочных значений коэффициента корреляции по Кендаллу. Этот эффект связан с большей чувствительностью первого коэффициента к несоответствию в тенденциях изменений значений признаков.
Для проверки значимости рангового коэффициента корреляции по Спирмену сформулируем основную гипотезу:
.
В качестве статистики критерия используют статистику
,
которая при условии истинности H0 и большом объёме выборки (n > 30) аппроксимируется стандартизованным нормальным распределением: .
Критическая область для статистики критерия выбирается, исходя из вида альтернативной гипотезы.
Регрессионный анализ
Статистические модели
Для применения математических методов описания явлений необходимо, прежде всего, установить соотношения между величинами, характеризующими рассматриваемые явления. Каждое такое соотношение представляет собой математическую модель явления. Так, например, законы Ньютона представляют собой совокупность моделей механических явлений. Уравнения Максвелла в физике представляют собой математическую модель электродинамических явлений.
Пусть поведение системы описывается некоторой совокупностью величин, причём одни величины носят характер внешних воздействий на систему и называются её входными воздействиями (input variables), а другие представляют собой результат работы системы и называются откликами системы (responses) на входные воздействия.
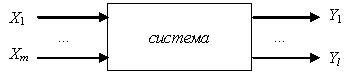
Во многих случаях математическую модель системы можно построить чисто математическим путём на основе известных законов механики, физики и других дисциплин, использующих количественные соотношения (такую модель будем называть теоретической). Так, например, различные модели управляемого летательного аппарата можно построить математически, пользуясь законами механики.
Однако существуют и такие системы, для которых принципиально невозможно построить модели чисто математическим путём. Примерами таких систем могут служить человек или коллектив людей, завод, отрасль промышленности, экономика и т.п. В этом случае приходится прибегать к экспериментальному исследованию самих систем или входящих в них подсистем и строить соответствующие модели путём статистической обработки полученных данных.
Модели, построенные на основе статистической обработки результатов экспериментального исследования функционирования систем, называются статистическими моделями систем.
Примерами задач, при решении которых используются статистические модели, могут служить прогнозирование погоды по измеренным значениями параметров состояния атмосферы в различных точках пространства и в различные моменты времени, в медицинской практике задача распознавания болезни пациента по результатам обследования и определение соответствующих методов лечения, распознавание рукописных символов и цифр на изображении и многие другие задачи, для решения которых применение классических математических методов оказывается неэффективным.
Задача построения статистической модели явления, процесса или системы состоит в нахождении соотношений между величинами, описывающими течение данного явления, процесса или функционирование системы. Если эти соотношения позволяют по данным значениям входных величин однозначно определить значения выходных, то описываемая ими модель называется детерминированной. Если же выходы модели являются случайными величинами, то модель называется стохастической.
Как теоретические модели, выводимые математически из законов физики, химии, экономики или других областей науки, так и статистические модели, получаемые на основе статистической обработки результатов наблюдений, могут быть детерминированными или стохастическими.
Одному и тому же явлению могут соответствовать различные модели. Проблема построения модели системы включает выбор подходящей формы этой модели, а также разумной степени её сложности.
Задачи регрессионного анализа
Рассмотрим задачу определения значения случайной величины по данным значениям другой величины. Пусть Y – случайная величина, значения которой требуется определить, x – известная величина, которая может представлять собой значение некоторой случайной величины X или заданное значение некоторой переменной. Предположим, что между величинами Y и X имеется статистическая связь, т.е. распределение случайной величины Y зависит от значения x.
С точки зрения математической статистики поставленная задача представляет собой задачу оценивания значения случайной величины Y при данном значении x. Пусть – оценка значения случайной величины Y при данном значении x. В связи с тем, что x – фиксированное значение, то оценка не является случайной величиной. Случайной величиной является ошибка этой оценки:
|
. |
В качестве меры точности оценки целесообразно использовать математическое ожидание квадрата ошибки :
|
. |
Наилучшей оценкой значения случайной величины Y при данном значении x будет оценка, минимизирующая ошибку (2):
|
. |
Из известного в теории вероятностей равенства
|
|
следует, что математическое ожидание квадрата ошибки (1) будет минимальным, если будет математическим ожиданием случайной величины Y при данном значении x:
|
. |
Следовательно, зависимость оценки значения случайной величины Y при данном значении x представляет собой регрессию Y на X. Таким образом, оптимальной с точки зрения среднего квадрата ошибки (1) оценкой зависимости Y от x служит регрессия Y на X. В частности, оптимальным прогнозом величины Y по данному значению x будет прогноз по регрессии.
Модель, определяемая регрессией Y на X, называется регрессионной моделью. Построение и исследование регрессионных моделей составляет предмет регрессионного анализа.
Регрессионную модель имеет смысл строить, если априорно или по результатам предварительного анализа выявлено, что между входными и выходными величинами имеется статистическая связь. В терминах регрессионного анализа входные величины называются регрессорами, или предикторами, а выходные переменные - откликами модели.
Ниже перечислены основные задачи регрессионного анализа.
1) Выбор класса функций для описания зависимости откликов модели от регрессоров .
2) Нахождение оценок неизвестных параметров функции, описывающей зависимость откликов модели от регрессоров .
3) Статистический анализ найденной зависимости откликов модели от регрессоров .
4) Предсказание значений откликов модели по результатам наблюдения регрессоров на основе найденной зависимости.
Рассмотрим случай одного регрессора X и скалярного отклика Y.
Как показано выше, оптимальной функцией, описывающей зависимость отклика модели Y от регрессора X, является функция регрессии Y на X. При этом возможны следующие ситуации.
1) Вид функции регрессии известен, исходя из априорной информации о наблюдаемых величинах. Например, если известно, что случайные величины X и Y имеют нормальный закон распределения, то уравнение регрессии Y на X (как и X на Y) может быть только линейным.
2) Вид функции регрессии не известен или эта функция слишком сложна. В этой ситуации возможны следующие подходы к определению вида функции регрессии.
а) Исследователь задаёт некоторый ограниченный класс функций Ψ, например, линейные или полиномиальные функции, в котором предлагается искать функцию регрессии. Если этот класс функций не содержит «истинную» функцию регрессии, то минимум среднего квадрата ошибки при каждом значении x не может быть обеспечен. На практике ищут оценку зависимости в выбранном классе функций из условия минимума математического ожидания (2) квадрата ошибки в рассматриваемой области изменения величины x. Для выбора класса функций, в котором целесообразно искать функцию регрессии, нередко требуется проведение предварительного анализа результатов наблюдений.
б) Функция регрессии оценивается по результатам наблюдений. Такое оценивание основано на расчёте множества условных средних значений наблюдений отклика Y и аппроксимации линии регрессии по рассчитанным точкам.
Оценивание параметров уравнения регрессии. Метод наименьших квадратов
Как только определён класс функций Ψ, в котором предлагается искать функцию регрессии, возникает задача оценивания её параметров. Рассмотрим сначала случай одного регрессора X и скалярного отклика Y. Пусть – предполагаемая скалярная функция регрессии, – вектор неизвестных параметров.
Таким образом, принимая во внимание (1*) и (5*), случайная величина Y при фиксированном значении x представляет собой сумму двух слагаемых: неслучайной величины и случайной ошибки :
Модель (1) является регрессионной моделью отклика Y, а ошибка называется ошибкой регрессионной модели.
При оценивании и проведении статистического анализа регрессионной модели (1), как правило, выдвигаются следующие ключевые требования.
1°. Математическое ожидание ошибки модели для всех x из рассматриваемой области изменения равно нулю:
.
Если математическое ожидание , то это требование может быть обеспечено для любых предполагаемых функций регрессии со свободным членом, поскольку он берёт на себя возможное ненулевое математическое ожидание ошибок. В связи с этим выбор моделей со свободным членом, как правило, предпочтительнее.
Нарушение этого требования в общем случае приводит к смещённости оценок регрессионной модели.
2°. Вход модели X и ошибки модели для всех x из рассматриваемой области изменения – независимые случайные величины. Это требование называется требованием экзогенности входа модели.
Экзогенность входа X означает независимость случайной величины X от функционирования моделируемой системы. Значения экзогенных переменных определяются вне модели и не связаны с результатами работы системы.
Примером неэкзогенной модели является модель:
.
В этой модели вход , очевидно, зависит от ошибки модели .
Нарушение требования экзогенности приводит к существенному ухудшению статистических свойств оценок регрессионной модели.
Пусть (x1, y1),…,(xn, yn) – выборка наблюдений двумерного случайного вектора (X, Y), имеющего распределение FXY(x, y).
Оптимальным вектором параметров β будет вектор, при котором достигается минимум критерия (3*) при каждом x. В силу ограниченности объёма выборки в качестве меры точности регрессионной модели выберем оценку среднего квадрата ошибки при каждом выборочном значении :
которая в точности совпадает с выражением (2*) для остаточной дисперсии признака Y.
Таким образом, задача нахождения вектора параметров β – это задача минимизации критерия:
|
. |
Учитывая, что выборочная дисперсия случайной величины Y не зависит от β, критерий минимизации остаточной дисперсии (3) эквивалентен критерию максимизации показателя «эр-квадрат»:
Вектор , максимизирующий критерий (4), является точечной оценкой вектора параметров β функции регрессии, рассчитанной по выборке (x1, y1),…,(xn, yn). Метод расчёта вектора , основанный на минимизации критерия (4), называется методом наименьших квадратов (МНК), а рассчитанные с его помощью оценки называются МНК-оценками.
Поскольку показатель «эр-квадрат», минимизируемый в методе наименьших квадратов, характеризует долю вариации случайной величины Y, объяснённую функцией регрессии, суть метода наименьших квадратов состоит в подборе таких параметров функции регрессии из заданного класса функций Ψ, при которых она объясняет максимально возможную долю вариации признака Y.
Необходимым условием минимума функции является равенство нулю частных производных:
|
. |
Подставляя (2) в выражение (5), получим систему k уравнений с k неизвестными:
|
|
Разрешая эту систему относительно параметров , находим МНК-оценки параметров функции регрессии . Значение представляет собой МНК-оценку функции регрессии в точке x.
Таким образом, оценка регрессионной модели (1) имеет вид:
|
. |
Подставляя выборочные значения в модель (7), получим множество случайных величин , предсказанных моделью:
.
Реализациями случайных величин являются выборочные значения . Разности между наблюдаемыми значениями и расчётными значениями функции регрессии , называются регрессионными остатками (residuals):
, .
Регрессионные остатки являются реализациями случайных ошибок регрессионной модели (1) при значениях её входа, равных соответственно.
Можно показать, что при соблюдении требований 1° и 2° к регрессионной модели, оценки параметров функции регрессии и её значения в произвольной точке x являются состоятельными и несмещёнными.
Простейшая линейная регрессионная модель
Пусть функция регрессии Y на X имеет вид:
|
. |
Тогда регрессионная модель (1*) отклика Y выглядит следующим образом:
|
. |
Такая модель называется простейшей линейной регрессионной моделью (simple linear regression).
Используя метод наименьших квадратов, найдём оценки параметров модели . Запишем систему уравнений (6*):
решением которой являются оценки :
|
|
Таким образом, МНК-оценка значения простейшей линейной функции регрессии Y на X (1) в точке x имеет вид:
.
Заметим, что найденные МНК-оценки параметров простейшей линейной регрессии являются выборочными оценками теоретических значений (9*), рассчитанных для функции регрессии нормально распределённых случайных величин.
Оценки имеют следующие свойства:
1. они являются линейными функциями результатов наблюдений ;
2. состоятельность, т.е при , ;
3. несмещённость, т.е. , .
Пусть к регрессионной модели (2) наряду с требованиями 1° и 2° налагаются следующие дополнительные требования (условия Гаусса-Маркова).
3°. Неизменность дисперсии ошибок для всех x из рассматриваемой области определения:
Требование постоянства дисперсии произвольных случайных величин называется требованием их гомоскедастичности. Если дисперсии случайных величин различны, то такие величины называются гетероскедастичными.
Регрессионная модель называется гомоскедастичной, если гомоскедастичны её ошибки, т.е. если выполнено условие (4) для всех x из рассматриваемой области определения.
Наличие свойства гомоскедастичности ошибок простейшей линейной регрессионной модели связано с гомоскедастичностью наблюдаемой случайной величины Y при различных значениях x. Так, если при различных x дисперсии случайной величины Y различны, то регрессионная модель будет гетероскедастичной.
Иногда гетероскедастичность данных можно обнаружить визуально (например, на рисунке справа). Если диаграммы рассеяния не дают явной информации, тогда применяются статистические тесты на гомоскедастичность.
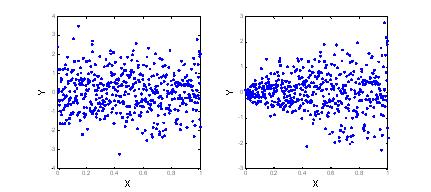
Наличие гетероскедастичности в наблюдениях случайной величины Y приводит к неэффективности оценок и .
4°. Независимость ошибок и модели для всех x и x' из рассматриваемой области определения.
Если известно, что ошибки модели имеют нормальное распределение при всех x, то требование независимости эквивалентно требованию некоррелированности:
.
Наличие свойства независимости остатков простейшей линейной регрессионной модели связано с независимостью наблюдаемых значений случайной величины Y при различных значениях x. Иными словами, выборка наблюдений должна быть реализацией независимой случайной выборки . Если это требование не выполняется, то МНК-оценки и являются неэффективными (теорема Гаусса-Маркова).
Свойства 3° и 4° эквивалентны выполнению условия
,
где Vε – ковариационная матрица ошибок регрессионной модели, I – единичная матрица.
При соблюдении требований 1°–4° оценки и являются эффективными, т.е. оценками с наименьшей дисперсией в классе всех линейных несмещённых оценок. Эти дисперсии равны:
Доверительные интервалы на уровне значимости α для параметров регрессионной модели рассчитываются по следующим формулам:
|
|
|
|
где – квантиль распределения Стьюдента с n–2 степенями свободы на уровне 1–α/2, – выборочная дисперсия случайной величины X, – несмещённая оценка остаточной дисперсии случайной величины Y:
,
Доверительный интервал на уровне значимости α для функции регрессии в точке x имеет вид:
Отметим, что границы доверительного интервала для функции регрессии f(x) нелинейно зависят от x.
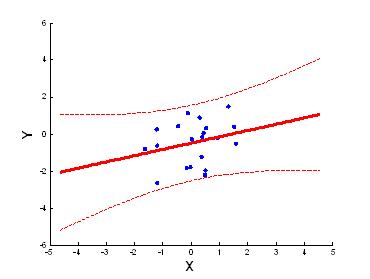
На рисунке сплошной линией изображена оцененная функция регрессии , пунктирными линиями – границы доверительного интервала для f(x) на уровне значимости α = 0,1.
Простейшая регрессионная модель (2) называется значимой, если .
Для проверки значимости простейшей регрессионной модели сформулируем основную и альтернативную гипотезы:
В качестве статистики критерия используется статистика:
которая при условии истинности H0 имеет распределение Фишера с 1 и n–2 степенями свободы в числителе и знаменателе соответственно: .
Критическая область для статистики критерия выбирается правосторонней.
Заметим, что статистика критерия (7), используемая при проверке значимости простейшей линейной регрессионной модели, представляет собой статистику (6*), используемую при проверке гипотезы о равенстве нулю коэффициента детерминации Y на X при числе неизвестных параметров функции регрессии k = 2. Фактически проверка гипотезы о значимости регрессионной модели – это проверка гипотезы о равенстве нулю коэффициента детерминации при функции регрессии (1).
Линейная регрессионная модель общего вида
Пусть функция регрессии имеет вид:
где – некоторая система функций (не обязательно линейных).
Тогда регрессионная модель (1*) отклика Y на входное воздействие x выглядит следующим образом:
где – случайная ошибка модели.
Такая модель называется линейной регрессионной моделью общего вида, или просто линейной регрессионной моделью. Под линейностью регрессионной модели понимается линейность по её параметрам .
Как правило, в качестве функции выбирается тождественная единица:
При условии постоянства математического ожидания ошибок модели такой выбор обеспечивает выполнение требования 1°, предъявляемого к регрессионным моделям.
Используя метод наименьших квадратов, найдём оценки параметров модели . Запишем систему уравнений (6*) в матричном виде:
где – вектор параметров модели, – вектор откликов модели,
|
. |
Матрица F называется регрессионной матрицей, или матрицей плана (design matrix).
Решением системы (4) является вектор:
МНК-оценка функции линейной регрессии Y на X (1) в точке x имеет вид:
При соблюдении требований к регрессионным моделям МНК-оценки (6) и (7) имеют те же свойства, что и МНК-оценки простейшей линейной регрессионной модели, а ковариационная матрица вектора МНК-оценок равна:
,
где σ2 – дисперсия ошибок модели (2). Матрица называется дисперсионной матрицей Фишера.
Доверительные интервалы на уровне значимости α для параметров , , регрессионной модели рассчитываются по следующим формулам:
где cjj – j-й диагональный элемент матрицы , , – квантиль распределения Стьюдента с n–k степенями свободы на уровне 1–α/2, – несмещённая оценка остаточной дисперсии случайной величины Y:
,
Доверительный интервал на уровне значимости α для функции регрессии в точке x имеет вид:
где – вектор значений системы функций в точке x.
Пример функции регрессии, линейной по параметрам, приведён на рисунке ниже.
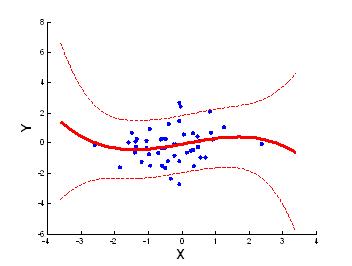
На рисунке сплошной линией изображена оцененная функция регрессии , пунктирными линиями – границы доверительного интервала для f(x) на уровне значимости α = 0,1.
Линейная регрессионная модель (2) называется значимой, если соответствующая ей функция регрессии зависит от x. В частности, если выполнено условие (3), то модель значима, если хотя бы один из коэффициентов отличен от нуля. Если все , то модель называется незначимой.
Проверка значимости линейной регрессионной модели означает проверку гипотезы:
против альтернативной гипотезы
.
В качестве статистики критерия используют статистику:
которая при условии истинности H0 имеет распределение Фишера с k–1 и n–k степенями свободы в числителе и в знаменателе соответственно: .
Критическая область для статистики критерия выбирается правосторонней.
Статистика критерия (8), используемая при проверке значимости линейной регрессионной модели, представляет собой статистику (6*), используемую при проверке гипотезы о равенстве нулю коэффициента детерминации Y на X при числе неизвестных параметров функции регрессии, равном k.
Для проверки гипотезы о равенстве нулю параметра , , линейной регрессионной модели:
используют статистику критерия:
,
которая при условии истинности H0 имеет распределение Стьюдента с n–k степенями свободы: .
Критическая область для статистики критерия выбирается, исходя из вида альтернативной гипотезы.
Система функций может быть выбрана произвольным образом, однако на практике удобно использовать некоторую систему ортогональных функций.
Система функций называется ортогональной на множестве , если
В случае центрированных функций , , т.е. функций, для которых выполнено условие:
, ,
равенство (9) в терминах математической статистики означает некоррелированность функций и при :
, , .
Можно показать, что если система функций ортогональна на множестве , то МНК-оценки параметров регрессионной модели (2) вычисляются по формуле:
, .
В качестве системы ортогональных функций могут быть выбраны, например, ортогональные полиномы Чебышева или Эрмита.
Множественная линейная регрессия
Если на систему действует множество входных воздействий , то её регрессионная модель имеет вид:
|
, |
где – функция регрессии, – случайная ошибка модели, – вектор входных воздействий. Пусть функция регрессии является линейной (по параметрам):
где – некоторая система скалярных функций (не обязательно линейных) m переменных.
Матрица плана регрессионной модели (1) аналогична матрице плана (5*) линейной регрессионной модели общего вида. МНК-оценки параметров функции регрессии (2) рассчитываются по формуле (6*).
Для расчёта доверительных интервалов параметров модели и проверки значимости модели используются те же формулы, что и для линейной регрессионной модели (2*).
Рассмотрим частный случай функции регрессии (2). Пусть , а функции заданы следующим образом:
Тогда функция регрессии (2) представляет собой гиперплоскость в пространстве признаков :
Пусть – выборка наблюдений случайного вектора . По этим данным может быть рассчитан показатель «эр-квадрат» (1*):
Этот показатель следует интерпретировать как долю вариации выборочных данных, объяснённую линейной функцией регрессии (2). Величина остаточной дисперсии характеризует разброс выборочных значений относительно гиперплоскости регрессии.
При анализе линейного уравнения регрессии (3) выборочное корреляционное отношение (4) называют также множественным коэффициентом корреляции (multiple correlation). Отметим, что множественный коэффициент корреляции, в отличие от линейного коэффициента корреляции Пирсона, принимает значения в диапазоне от 0 до 1.
Можно показать, что множественный коэффициент корреляции выражается через парные коэффициенты корреляции следующим образом:
где RXX – корреляционная матрица регрессоров размерности , c – вектор-столбец корреляций отклика Y с регрессорами .
В частном случае, при m = 2 формула (5) имеет вид:
.
Добавление в регрессионную модель новых регрессоров всегда увеличивает значение показателя «эр-квадрат». Связано это с тем, что с увеличением размерности пространства признаков ошибка линейной аппроксимации n точек может только уменьшиться либо остаться неизменной (при нулевом коэффициенте перед добавляемым признаком). Эта особенность является недостатком показателя «эр-квадрат», поскольку подобное увеличение его значения может быть не связано с наличием статистической связи между рассматриваемым откликом Y модели и переменными .
Показателем, компенсирующим этот эффект, является скорректированное корреляционное отношение:
,
при анализе линейного уравнения регрессии (3) называемое также скорректированным множественным коэффициентом корреляции (adjusted multiple correlation).